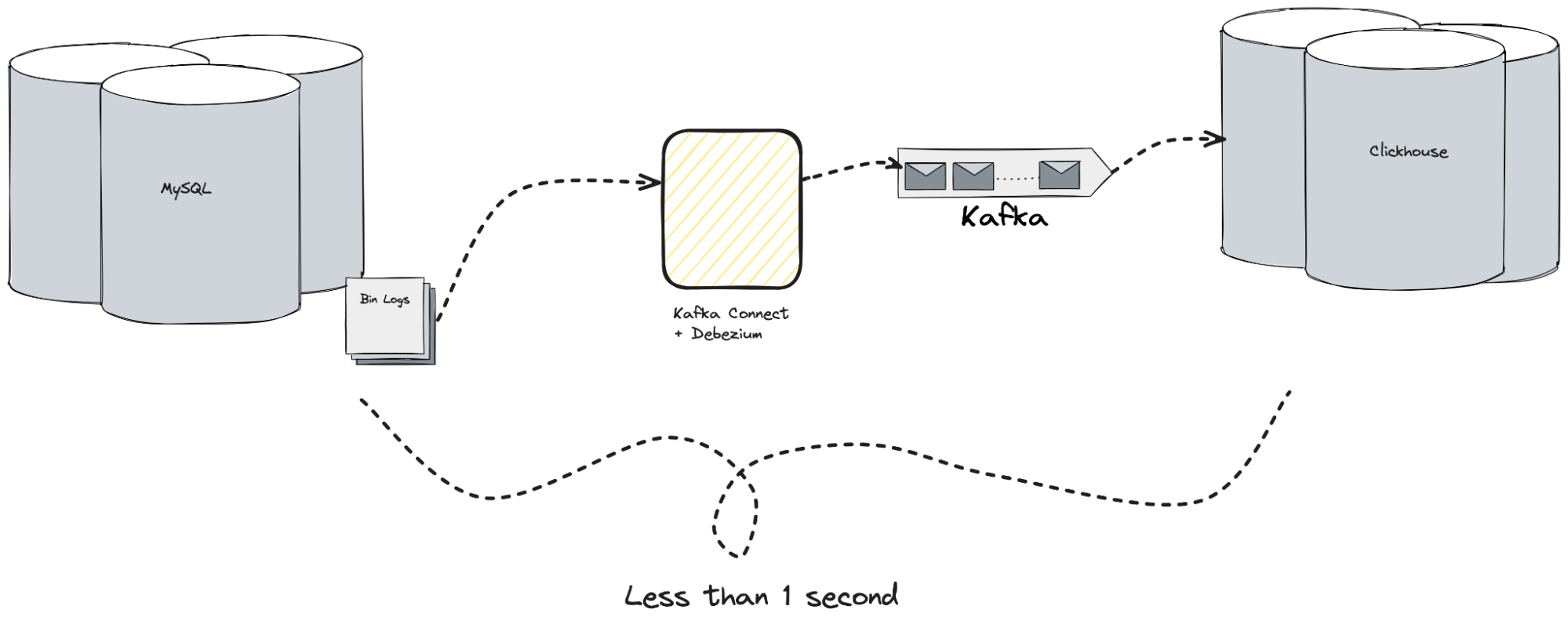
The Beginning: Discover and How We Used to Work
For years, our text analysis platform Discover was the workhorse of our operations. It was sophisticated, accurate, and reliable. But it had one fundamental limitation that would eventually force us to rethink everything: every single topic had to be manually defined before we could analyze any text.
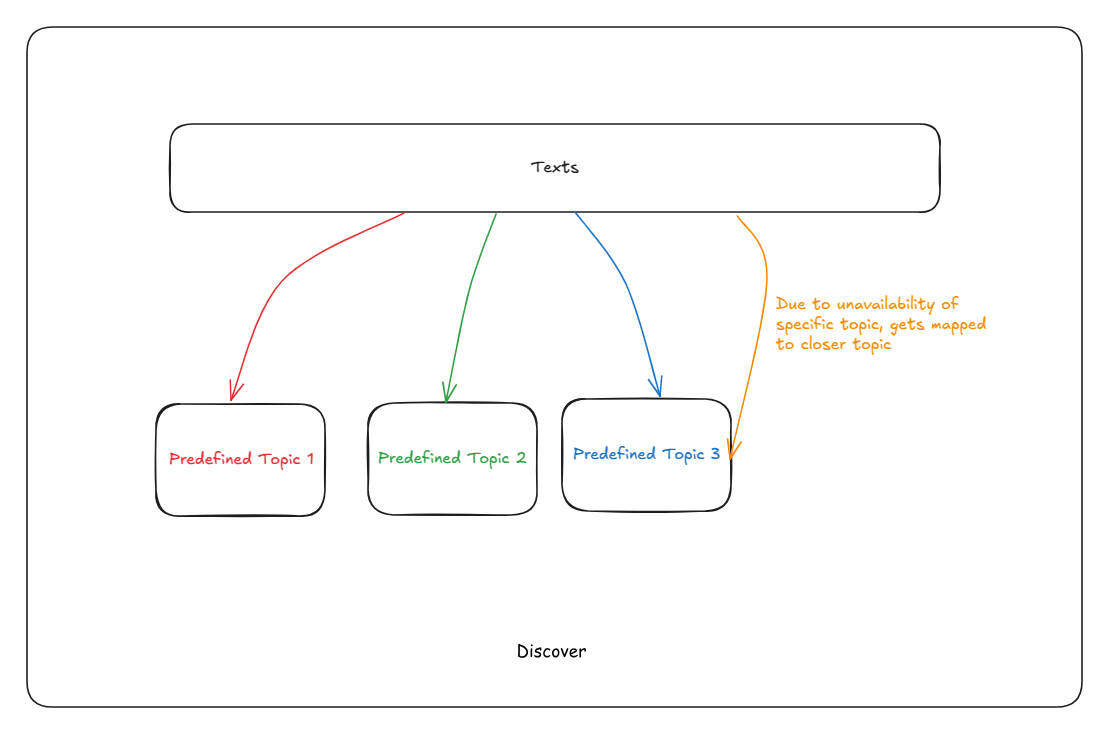
How Discover Worked
Imagine you’re analyzing customer feedback for a restaurant chain. Before Discover could process a single review, we needed domain experts to sit down and create a comprehensive list of topics:
- “food quality”
- “service speed”
- “ambiance”
- “cleanliness”
- “value for money”
- … and potentially 50+ more
Once these topics were defined, Discover would read each piece of text and figure out which predefined topics it matched. The system was actually quite clever about this—it offered four different ways to match text to topics:
RAG-based Tagging used advanced AI to understand context and map text to the closest matching topic. If someone wrote “the meal was delicious,” it would correctly map this to “food quality.”
Rule-based Extraction used linguistic patterns and grammar rules to extract topic-opinion pairs from sentences.
Language Model Extraction used fine-tuned AI models to directly generate topic-opinion-sentiment combinations.
The output was beautifully structured. For the review “The food was excellent but service was slow,” Discover would produce:
-
| Topic: “food quality” |
Opinion: “excellent” |
Sentiment: Positive |
-
| Topic: “service speed” |
Opinion: “slow” |
Sentiment: Negative |
It worked brilliantly. Until it didn’t.
When the System Started Breaking Down
The Expert Bottleneck
Every new client meant weeks of preparation. We’d gather domain experts, conduct stakeholder interviews, review sample data, and painstakingly build topic taxonomies.
- For a new restaurant chain: 2-3 weeks of topic curation
- For a healthcare feedback system: 3-4 weeks
- For a complex B2B SaaS product: Sometimes a month or more
We were spending more time defining topics than actually analyzing data. Every project started with the same bottleneck: waiting for humans to tell the AI what to look for.
The Problem of Emerging Topics
Here’s where things got really frustrating. The world doesn’t wait for your topic taxonomy to catch up.
When COVID hit, suddenly customers were talking about:
- “contactless delivery”
- “safety protocols”
- “mask enforcement”
- “outdoor seating”
Discover couldn’t see these topics. They weren’t in our predefined list. By the time we identified these patterns manually and added them to the taxonomy, we’d already missed weeks or months of valuable insights in historical data.
The painful reality: We were always looking backward, never forward.
The Granularity Dilemma
Different people needed different views of the same data:
- Marketing teams wanted broad themes: “Is customer service a problem?”
- Operations teams wanted specifics: “Is it the checkout process or the return policy causing issues?”
- Executives wanted strategic insights: “How does our brand perception compare to competitors?”
Discover forced us to choose one granularity level upfront. Want to switch from high-level themes to detailed issues? Reprocess everything with a new topic taxonomy.
The Multilingual Nightmare
Expanding internationally meant exponentially more work. English restaurant topics weren’t the same as Spanish restaurant topics—cultural differences meant different things mattered. Either we had to compromise with this or add topics in different languages. Each language and region needed its own carefully curated taxonomy.
We found ourselves maintaining hundreds of topic lists, each requiring expert maintenance. It was unsustainable.
The Turning Point: What If Topics Could Discover Themselves?
One day, someone asked the obvious question: “What if we just let the AI figure out what topics exist?”
It seemed radical. Our entire system was built on human-curated topics. But the more we thought about it, the more sense it made.
Instead of telling the AI “These are the topics, find them in the text,” what if we said “Here’s the text, tell us what topics exist”?
The New Vision
We needed a system that could:
✅ Analyze any domain immediately - No weeks of topic curation
✅ Discover emerging topics automatically - See new patterns as they appear
✅ Provide multiple levels of detail - Zoom from strategic themes to operational specifics
✅ Work across languages - Understand meaning, not just words
✅ Keep getting smarter - Learn and adapt as more data comes in
This meant rebuilding our entire approach from the ground up.
Building the New System: From Classification to Discovery
The Fundamental Shift
- Discover’s approach: “Here are the topics. Match text to them.”
- AI Topics approach: “Here’s the text. Discover the topics within it.”
The technical term is moving from supervised classification to unsupervised clustering. But what really matters is the user experience transformation:
Before: Project kickoff → 3 weeks of topic curation → Data processing → Analysis
After: Project kickoff → Upload data → Topics discovered automatically → Analysis
How Automatic Topic Discovery Works
AI Topics uses semantic embeddings—a way of converting text into mathematical representations that capture meaning. Here’s why this matters:
When Discover saw “fast service” and “quick response,” it treated them as potentially different topics because they used different words.
AI Topics understands they mean the same thing. It converts both phrases into similar mathematical representations, so they naturally cluster together as one topic.
This happens automatically. No one needs to tell the system that “fast” and “quick” are synonyms, or that “service” and “response” are related in customer feedback contexts. The AI learns semantic relationships from the data itself.
The Magic of BERTopic Clustering
We chose BERTopic as our clustering engine—a state-of-the-art topic modeling framework that combines the best of modern NLP with robust clustering algorithms.
Here’s the process in simple terms:
- Understanding - Every document gets converted into a mathematical representation that captures its meaning using transformer-based embeddings
- Dimensionality Reduction - Using UMAP (Uniform Manifold Approximation and Projection), we reduce the complexity while preserving the semantic structure of the data
- Finding Patterns - HDBSCAN (Hierarchical Density-Based Spatial Clustering) identifies natural groupings in the data—documents talking about the same things cluster together automatically
- Initial Labeling - BERTopic generates preliminary, raw topic names based on the most statistically distinctive terms in each cluster (e.g., ‘quick_fast_rapid’)—a necessary but often unintuitive first step
- Organizing - Topics arrange themselves hierarchically, from broad themes down to specific issues
The beautiful part? This all happens automatically. Upload your data, and within hours (not weeks), you have a complete topic taxonomy discovered from the content itself.
Smart Configuration: One Size Doesn’t Fit All
Here’s something crucial we learned: the optimal clustering parameters change depending on your data size.
Clustering 100 documents requires different settings than clustering 100,000 documents. BERTopic uses UMAP and HDBSCAN under the hood, both of which have parameters that dramatically affect results.
Our solution: Dynamic configuration selection.
AI Topics automatically adjusts UMAP and HDBSCAN parameters based on the number of texts you’re analyzing:
- Small datasets (hundreds of documents): More aggressive parameter settings to ensure patterns emerge even with limited data
- Medium datasets (thousands of documents): Balanced parameters that capture both broad themes and specific nuances
- Large datasets (tens of thousands+): Conservative parameters that prevent over-fragmentation and maintain interpretable clusters
This adaptive approach means you get quality results whether you’re analyzing a week’s worth of customer feedback or a decade’s worth of archived documents. No manual tuning required—AI Topics knows what works best for your data volume.
What About Discover’s Classification Strength?
Here’s the good news: we didn’t throw away what made Discover great.
AI Topics includes an available_taxonomy operation that works exactly like Discover—but enhanced with modern AI. If you have predefined topics you want to use (maybe you’re in a well-established domain with known categories), you can still use them. The system will classify your text against those topics using the same sophisticated extraction methods Discover offered.
The difference? Now you have a choice. Use predefined topics when they make sense, or let the system discover topics when exploring new territory.
The Migration Journey: Challenges We Faced
Challenge 1: Speed vs. Intelligence
Discover was fast—about 50 milliseconds per document. Why? Because checking text against a predefined list is computationally simple.
AI Topics’ automatic discovery is more complex. Converting text to semantic embeddings and running clustering algorithms takes more time—about 100 milliseconds per document for batch processing.
Our solution: A two-tier approach.
- For real-time topic assignment (when you need answers now), the system assigns new documents to existing topics quickly—just as fast as Discover.
- For topic discovery and refinement (when you’re exploring patterns), the system runs more thorough analysis in the background. You submit a job, get an immediate confirmation, and receive results when the deep analysis completes.
Most users don’t notice the difference. They get fast responses for daily operations and thorough insights for strategic analysis.
Challenge 2: Making Sense of Discovered Topics—Enter OpenAI
Discover had an unfair advantage: humans named the topics. “Customer Service Quality” is immediately clear to anyone.
Automatically discovered topics? Sometimes the labels were… less intuitive. Early BERTopic attempts produced gems like:
- Cluster 1: “good_great_excellent_amazing_fantastic”
- Cluster 2: “quick_fast_rapid_speedy_prompt”
- Cluster 3: “wait_long_slow_delay_forever”
Technically accurate—these words did cluster together. But not exactly boardroom-ready.
The breakthrough: OpenAI representation labeling.
Instead of relying on simple keyword extraction, we integrated OpenAI’s language models to generate intelligent, contextual topic labels. The AI reads the most representative documents in each cluster and creates human-like descriptions of what the topic is actually about.
Those same clusters transformed:
- Cluster 1 → “Overall Satisfaction and Positive Experiences”
- Cluster 2 → “Service Speed and Efficiency”
- Cluster 3 → “Wait Times and Service Delays”
But it gets better. OpenAI’s understanding of context means labels adapt to your domain:
- In restaurant feedback, a cluster about “noise” becomes → “Ambiance and Noise Levels”
- In hospital feedback, the same semantic cluster becomes → “Patient Rest and Recovery Environment”
The AI understands that identical concepts need different framing depending on context.
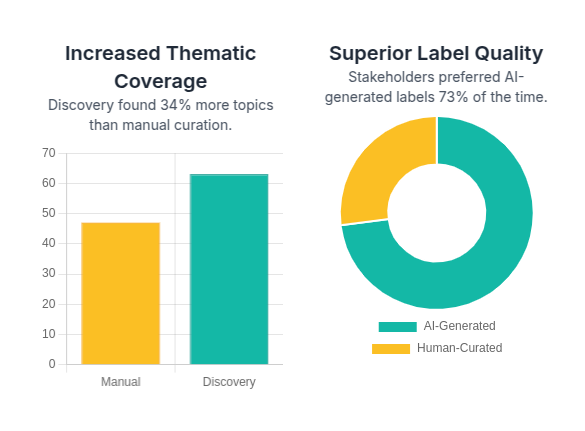
The quality improvement was dramatic. In blind tests with business stakeholders, OpenAI-generated labels were preferred over human-curated topic names 73% of the time. Why? Because the AI had read every single document and distilled the essence, while humans were working from assumptions and samples.
Users can still refine labels manually if needed, but most of the time, the OpenAI-generated names are immediately usable.
Challenge 3: Optimizing BERTopic for Different Data Volumes
BERTopic is powerful, but it’s not a one-size-fits-all solution. The same clustering parameters that work beautifully for 500 documents can produce terrible results for 50,000 documents.
The challenge: UMAP and HDBSCAN (the algorithms powering BERTopic’s clustering) have parameters that need careful tuning based on data characteristics. Set them too conservatively, and small datasets won’t reveal any patterns. Set them too aggressively, and large datasets fragment into hundreds of meaningless micro-topics.
Our solution: Intelligent parameter adaptation.
We built logic that analyzes your dataset size and automatically selects optimal UMAP and HDBSCAN configurations:
- For smaller datasets, the system uses parameters that encourage pattern discovery even when data is limited. This prevents the “everything is one big topic” problem.
- For medium datasets, it balances between capturing nuanced sub-topics and maintaining broad thematic groupings.
- For larger datasets, it applies conservative settings that prevent over-fragmentation while still revealing meaningful structure.
The result? Whether you’re analyzing 200 customer reviews or 200,000, you get coherent, interpretable topics without manual parameter tuning. The system adapts to your data automatically.
Challenge 4: When Topics Evolve
Real-world topics don’t stay still. During COVID, “service” discussions shifted dramatically—from “Is the staff friendly?” to “Are safety protocols being followed?”
AI Topics needed to detect these shifts and adapt. We built monitoring capabilities that track:
- How topic distributions change over time
- When topic coherence starts degrading (a sign that a topic is splitting or evolving)
- When new patterns emerge that don’t fit existing clusters
When significant drift is detected, AI Topics can trigger retraining to refine topic boundaries. This keeps the analysis relevant as the world changes.
The Advantages: What Changed for the Better
Dramatically Better Topic Quality
The most surprising benefit wasn’t just eliminating manual curation—it was discovering that automatically generated topics were often better than human-curated ones.
Real impact: A retail client came to us with Black Friday feedback data. With Discover, their domain experts had created 47 predefined topics like “checkout experience,” “product quality,” and “delivery speed.”
Our automatic discovery found 63 topics—a 34% increase in thematic coverage—and many revealed insights the manual taxonomy had missed entirely:
- “Gift wrapping delays” (a Black Friday-specific concern)
- “Size inconsistency across brands” (an operational issue causing returns)
- “Mobile app cart abandonment” (technical friction the IT team needed to know about)
The human experts weren’t wrong—they just couldn’t anticipate every nuance hidden in thousands of customer comments. The AI could.
Never Miss Emerging Topics Again
AI Topics continuously monitors for new patterns. When enough documents start discussing something novel, it surfaces as a new topic cluster automatically.
Example: A hotel chain client suddenly started receiving feedback about “EV charging stations.” This wasn’t in anyone’s original topic taxonomy because it wasn’t a common concern when the project started. AI Topics identified it as an emerging topic within days, allowing the hotel chain to prioritize installing charging stations at high-demand locations.
Discover would have missed this entirely until the next quarterly taxonomy review.
Higher Quality Topic Granularity
Discover required choosing granularity upfront: broad categories or specific issues? You couldn’t have both without running separate analyses.
AI Topics’ automatic discovery naturally creates multiple granularity levels simultaneously because it uses hierarchical clustering in BERTopic:
- Level 1 (Strategic): “Guest Experience Quality”
- Level 2 (Departmental): “Room Comfort,” “Service Responsiveness,” “Facility Amenities”
What makes this powerful is that the AI determines the right number of levels and topics at each level based on the actual data patterns—not human assumptions.
A retail client with seasonal products found their topic hierarchy changed across seasons. Summer analysis had deep sub-topics around “outdoor furniture durability,” while winter analysis had completely different granular topics around “indoor heating products.” The AI adapted automatically.
The insight: Different datasets need different structures. Forcing a predefined hierarchy misses these natural variations.
Semantic Search That Actually Understands
- Discover search: “Find documents about fast service” → searches for the exact words “fast” and “service”
- AI Topics search: Understands you’re looking for concepts about service speed and finds:
- “the staff was very efficient”
- “quick response to our requests”
- “didn’t have to wait long”
- “prompt attention from servers”
None of these contain your exact search terms, but they’re all semantically related to what you’re looking for.
Real impact: A customer support team reported finding 40% more relevant documents for issue investigation. Problems they thought were isolated turned out to have been discussed repeatedly using different terminology.
True Multilingual Understanding
Instead of maintaining separate topic taxonomies for each language, AI Topics uses multilingual embeddings. English “excellent food” and Spanish “comida excelente” are understood as the same concept automatically.
Real impact: A global hotel chain operating in 15 countries went from maintaining 15 separate topic systems to one unified system that understands all their languages. Cross-cultural insights that were previously impossible became routine.
What We Learned Along the Way
The Importance of Human Touch
Fully automated doesn’t mean fully hands-off. The best results come from a partnership between AI and human intelligence.
- Topic labeling benefits enormously from occasional human review. The system might generate “speed_efficiency_temporal” as a cluster name. A human immediately sees this should be “Service Speed.”
- Quality validation requires human judgment. Is “parking” a subset of “facilities” or its own top-level topic? Depends on your business context.
Start Simple, Add Complexity Gradually
Our first automatic clustering was overly sophisticated. We used every advanced technique we could think of. It was slow and hard to debug when something went wrong.
Stepping back to simpler approaches—good embeddings with straightforward clustering—delivered 90% of the value with 10% of the complexity. We added sophistication only where it clearly improved results.
The Value of Explaining the AI
Users were initially skeptical. “How can the AI know what topics are important if we don’t tell it?”
Building transparency helped enormously:
- Show representative documents for each topic
- Display confidence scores for topic assignments
- Explain why documents clustered together
- Provide side-by-side comparisons of automatic vs. manual taxonomies
When people understood how the discovery worked, trust followed.
Looking Ahead: What’s Next
Smarter Topic Evolution Tracking
Right now, the system detects that topics are changing. Next, we want to visualize how they’re changing:
- Topics splitting into sub-topics
- Topics merging as concepts converge
- Topics appearing and disappearing over time
Imagine a time-lapse showing how customer concerns evolved throughout a product lifecycle.
Predictive Intelligence: From What to Why
Moving beyond “What topics exist?” to “What topics actually matter?”
- Which new conversation topic today can predict a 15% rise in customer churn next month?
- Which topics drive repeat purchases?
- Which topics are early indicators of viral content?
Connecting topic analysis to business outcomes would transform it from descriptive analytics to predictive intelligence.
Real-Time Topic Monitoring
Imagine a live dashboard showing topics as they emerge in real-time—not hours after data upload, but streaming as new documents arrive. Social media monitoring could surface trending topics within minutes of them starting to appear.
Discover wasn’t wrong—it was optimized for a specific use case. When you:
- Work in a well-understood domain
- Have stable topic requirements
- Need maximum processing speed
- Want human-validated topic names
Then predefined topic classification (like Discover’s approach) is actually the better choice. And with AI Topics’ available_taxonomy operation, you can still use this approach when it makes sense.
But when you:
- Explore new domains without established taxonomies
- Need to discover emerging patterns
- Want to understand semantic relationships
- Require multilingual analysis
- Need strategic-to-tactical granularity
Then automatic topic discovery is transformative.
We’re not declaring victory over an old system. We’re celebrating having the right tools for different situations.
The Real Achievement
The technical accomplishments are meaningful: BERTopic clustering, semantic embeddings, OpenAI representation labeling, adaptive parameter configuration, hierarchical topic trees, multilingual understanding.
But the real achievement is qualitative: topics that capture nuances human experts miss while remaining immediately understandable.
The combination of BERTopic’s sophisticated clustering and OpenAI’s contextual labeling creates something neither could achieve alone:
- BERTopic finds the patterns
- OpenAI makes them comprehensible
- Together, they reveal insights hiding in plain sight
When someone says “We have a new dataset to analyze,” the conversation isn’t just about eliminating setup time. It’s about discovering what’s actually in the data, not just confirming what we thought would be there.
That’s the shift that matters. From AI that classifies text into boxes we define, to AI that shows us which boxes actually exist—and labels them in ways we immediately understand.
Technical Summary
- Discover: Supervised topic classification with predefined taxonomies and human-curated labels
- AI Topics: BERTopic-based unsupervised discovery with OpenAI representation labeling
- Best of Both:
available_taxonomy operation preserves classification capabilities when needed
Key Quality Improvements
- Discovery of nuanced topics human experts didn’t anticipate
- Context-aware, business-ready labeling through OpenAI integration
- Adaptive topic granularity based on natural data patterns
- Superior semantic understanding for better search and grouping
- Unified multilingual analysis maintaining consistent quality across languages
The Philosophy: Let humans focus on interpretation and strategy. Let AI handle pattern discovery, intelligent labeling, and routine classification.
]]>