

Introducción
NPS (Net Promoter Score) es una metodología ampliamente utilizada para medir la satisfacción de los clientes. De hecho, es casi omnipresente y ha ganado muchos seguidores en todo el mundo, principalmente por su simplicidad y, lo que es igualmente importante, como una medida para predecir la lealtad del cliente y, a su vez, la rentabilidad.
También sabemos que Customer Churn es la única medida que puede sostener a las empresas en los buenos y malos momentos. Sin embargo, determinar y, lo que es más importante, predecir el Churn sin un equipo de ciencia de datos dedicado a esto es casi imposible. La mayoría de los equipos de ciencia de datos observan los comportamientos e intentan correlacionar una multitud de variables de comportamiento para las variables de salida. Si bien esto es teóricamente cierto, esto casi nunca les da a los investigadores el «por qué»; solo brinda un modelo correlacional, no un modelo causal.
En este documento técnico, mostramos una mejora en el modelo NPS: incluir una manera operativa y cognitivamente fácil de
- Aislar e identificar las razones del abandono, et al.
- Auto-Identificación – Establece un modelo para actualizar de forma dinámica y automática los motivos.
- Predicción de abandono – Basado en las comparaciones de Razón-Identificación de Pasivos vs. Detractores.
Tabla de contenidos
- Introducción
- Programas NPS – Usar plataforma/proceso/modelos existentes
- Aislamiento
- Identificar
- Predecir
- Uber: Ejemplos de identificación de Churn
- Intención declarada Vs. Intención real – Mercados saturados
- Conclusión
Programas NPS – Usar plataforma/proceso/modelos existentes
Encuestas de Salida / Cancelación: La mayoría de los programas de NPS ya cuentan con modelos para comunicarse con los clientes después de que cancelan/abandonan y determinan las razones de la fuga.
La mayoría de los programas de NPS ya cuentan con modelos para comunicarse con los clientes después de que cancelan/abandonan y determinan las razones de la fuga. Esto es post-facto y, si bien brinda buenos indicadores direccionales, ponerlo en práctica ha sido un desafío. Esto se debe en parte a que las razones cambian con el tiempo y no existe una comparación «Base». Por comparación básica, queremos decir que si solo estamos encuestando a los clientes que cancelan/abandonan, entonces es muy difícil comparar eso con las personas que NO están cancelando: clientes existentes.
NPS en curso / Encuestas de registro
Las empresas que usan NPS como una base continua para los clientes existentes pueden usar ese mismo modelo para determinar y predecir la rotación. El beneficio de usar encuestas operativas continuas para determinar Churn es que ya está implementado: la capacidad de enviar notificaciones por correo electrónico/sms, publicar transacciones y recopilar datos.
Si bien es fácil determinar el NPS, determinar dinámicamente la causa raíz/aislar e identificar las causas raíz se ha relegado al análisis de texto sobre «¿Por qué?»
Para las encuestas, la mayoría de los modelos de análisis de texto no funcionan, en parte debido a los datos de NLP/Entrenamiento. Los buenos modelos de Machine Learning necesitan muchos datos de entrenamiento para aumentar la precisión.
En esta solución, determinamos funcionalmente la respuesta «Por qué» utilizando la inteligencia colectiva de los propios clientes.
Aislamiento
La primera tarea a mano es el aislamiento. Por aislamiento, nos referimos a determinar una o dos razones principales por las que alguien tiene altas probabilidades de abandonarnos. Cada producto / servicio tiene algunos elementos únicos y clave que determinan la afinidad del cliente e inversamente determinan la rotación del cliente. La primera idea clave aquí es aislar estas razones clave. Esto no se puede hacer usando análisis de texto, simplemente porque las herramientas de IA/PNL aún no son lo suficientemente buenas para determinar el «peso» en torno a diferentes razones del texto simple.
Podemos gastar mucha energía, tiempo y esfuerzo en afirmar que las herramientas de IA/PNL llegarán algún día, pero es 2020 y todavía tengo que conocer a un cliente que pueda decirme con confianza que su confianza en su modelo de PNL es lo suficientemente alto como para tomar esta determinación.
Estamos mostrando un enfoque mucho más simple para esto. Dejamos que el cliente elija entre un conjunto de «razones» cuando realiza una encuesta NPS. Aquí hay un ejemplo a continuación;
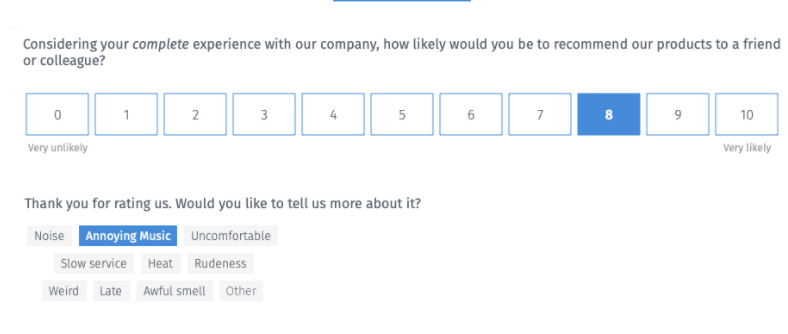
Permitimos a los usuarios elegir entre 1, 2 o 3 elementos; esto es necesario para el aislamiento. Puede haber muchas razones para la rotación, pero estamos obligando a los encuestados a elegir las razones «principales» para la rotación. Este proceso permite el aislamiento de los motivos de forma automática.
Identificar
La siguiente parte es la identificación concreta. El argumento típico contra el uso de un modelo como este, donde las razones están predeterminadas, es que estas razones pueden no ser exhaustivas. Esto es correcto. Para solucionar esto, nosotros solemos incluir una opción de «Otros». Permite que el encuestado ingrese sus propias razones para otorgar el puntaje NPS.
Hay 2 ideas clave que se aplican aquí.
- Contexto enfocado: no queremos que los encuestados divaguen sobre muchas cosas diferentes. Necesitamos identificar el motivo principal y dado que el motivo principal no está en la lista de opciones, pueden ingresar el motivo.
- Texto limitado: también sabemos que limitar el texto a 1 o 2 líneas (como los 140 caracteres de Twitter) centra la atención del cliente y se concentra en la causa raíz. También permite la identificación de temas en lugar del análisis de sentimientos. Realmente no necesitamos más análisis de sentimientos, ya conocemos el NPS. La clave aquí es la identificación precisa del tema.
Además, utilizamos un diccionario de datos/contenido para determinar los «temas» utilizando un modelo de texto/PNL. Nuevamente, esto sería mucho más preciso, porque solo estamos buscando «Temas» que el usuario debe escribir, es decir, sustantivos, «El servidor fue grosero» o «No hay suficientes opciones», donde estamos modelando esto para la identificación automática de los temas.
AI/ML para el descubrimiento de temas
QuestionPro se ha asociado con Bryght.ai y utilizará ese modelo AI/ML para la identificación de temas.

Una de las razones de esto es que hemos trabajado con el equipo de Bryght para desarrollar diccionarios de datos en verticales múltiples y únicos, incluidos juegos, comercio minorista, Gig-Economy, B2B SaaS, etc. Estos diccionarios de datos personalizados basados en el conocimiento verticalizado de la industria nos brindan una precisión mejor y más enfocada.
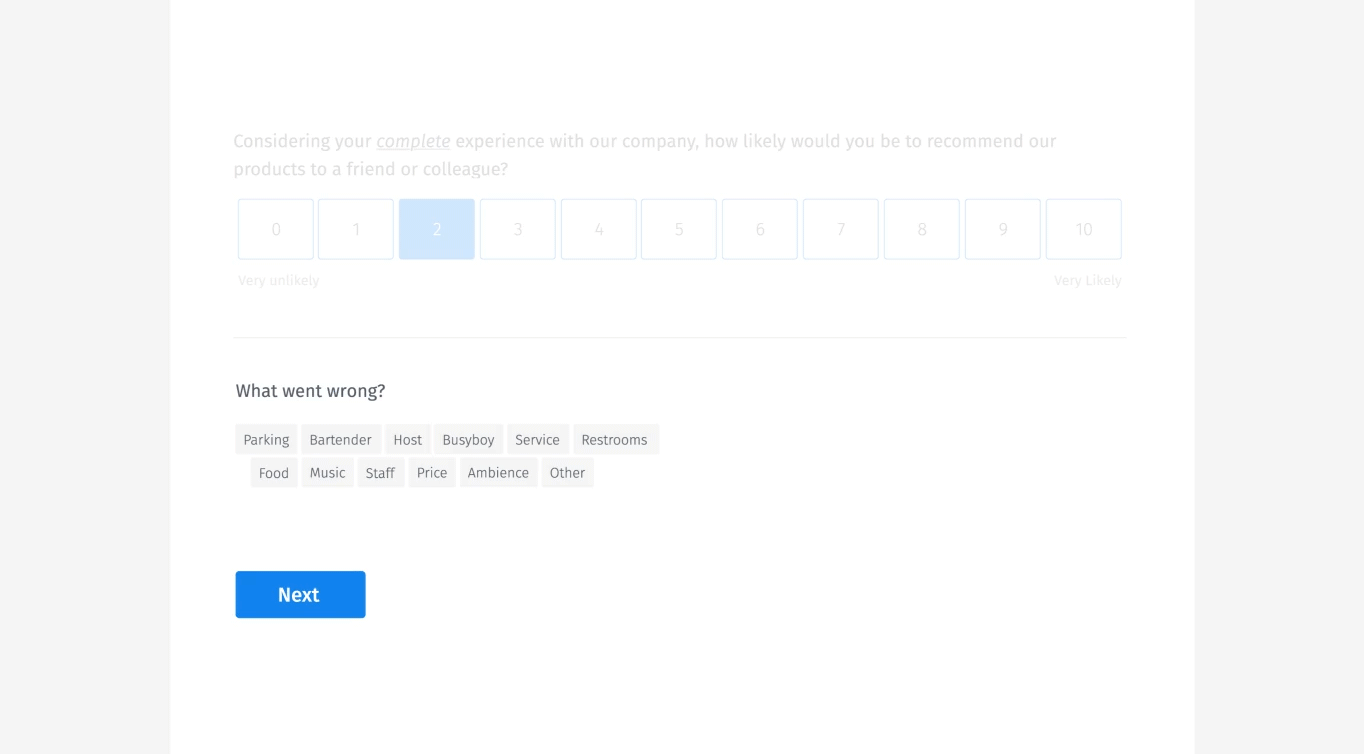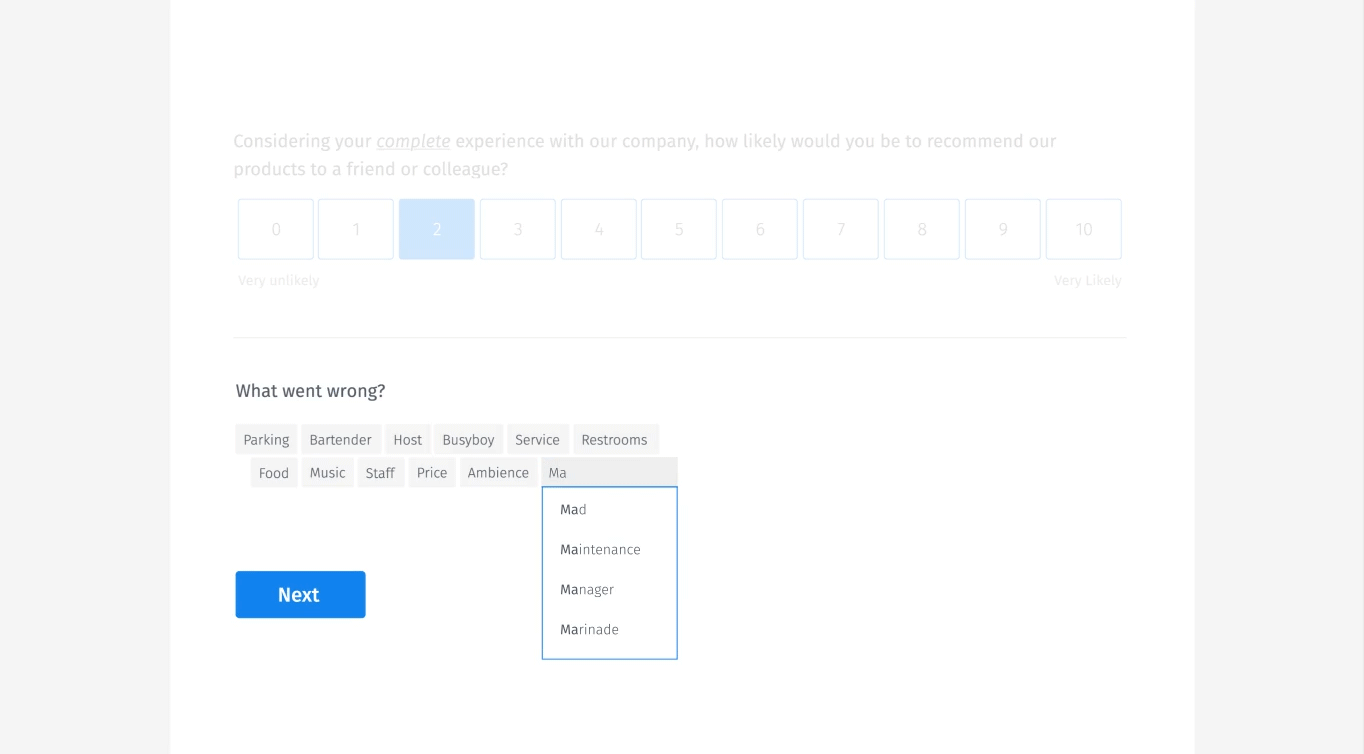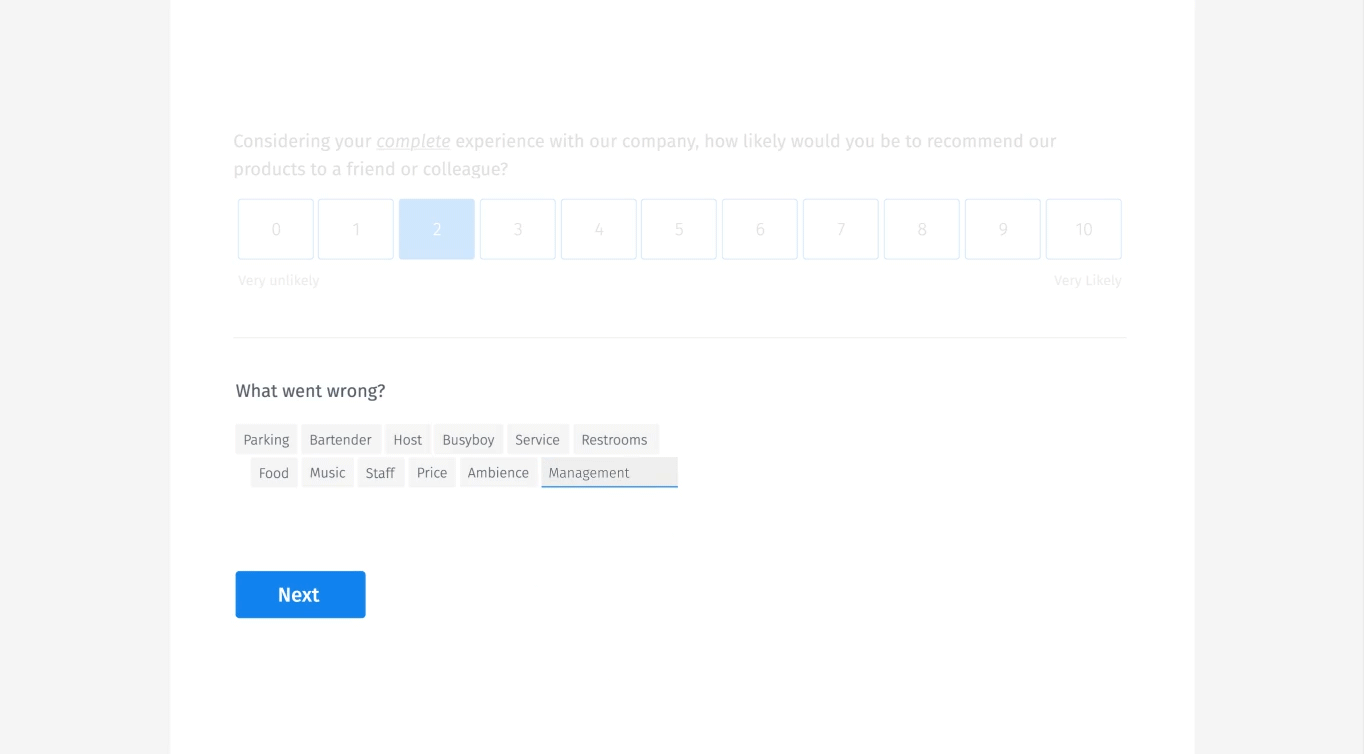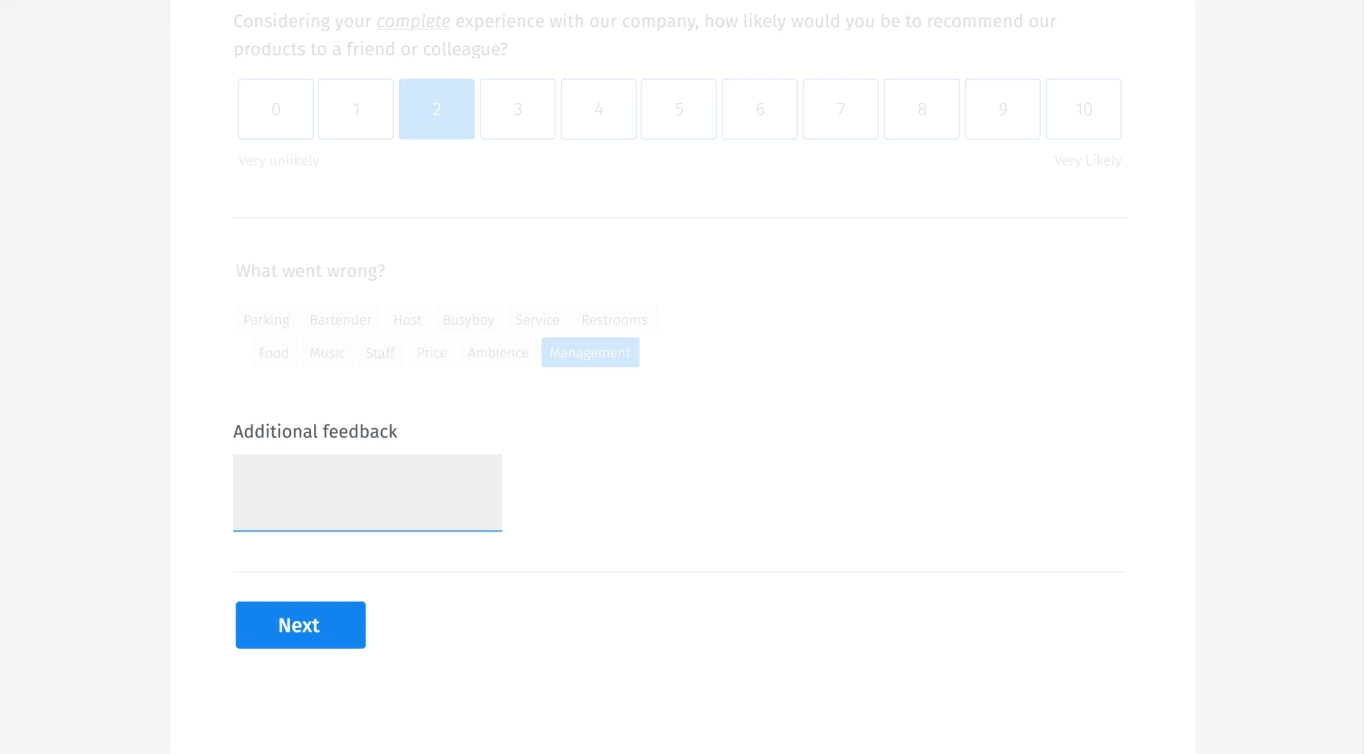
Sugerencias predictivas
También hacemos sugerencias predictivas, muy similares a Google Suggest. A medida que los usuarios escriben, les mostramos lo que otros han sugerido. Esto permite a los usuarios simplemente elegir el elemento, en lugar de expandir exponencialmente el diccionario de datos.
Aquí hay un ejemplo de cómo lo haríamos visualmente.
Predecir
Hasta ahora, con los modelos de Identificación y Aislamiento anteriores, podemos decir de manera determinista que las razones a, b y c son las razones principales por las que la gente está insatisfecha/detractora y, por lo tanto, se supone que todos tienen una propensión del 100 % a abandonar. Creemos que es lógico utilizar detractores para identificar y aislar las razones del churn. Suponemos que los detractores ya están agitados y, en este punto, sería casi imposible evitarlo.
Las personas pasivas son los «indecisos», están vacilantes, pero podrían inclinarse hacia cualquier lado. En nuestro modelo de predicción, les pedimos a las personas pasivas que elijan exactamente el mismo conjunto de razones que dieron a los detractores. Esto nos permite comparar el Pasivo con los Detractores e identificar y predecir con precisión las personas pasivas que abandonarán.
Tomemos un ejemplo real y analicemos esto. Supongamos que hay 5 razones por las que los detractores han elegido.
- Servicio Pobre [80%]
- Mesas Sucias [30%]
- Insuficientes opciones en el menú [18%]
- Precio [12%]
- Ubicación [21%]
Estos porcentajes no suman 100 porque hemos permitido a los usuarios elegir hasta 3 razones para dar una puntuación de detractor. Como se describió anteriormente, este modelo de aislamiento puede estar entre 1 y 3 (elija la razón principal o las 2 razones principales).
Para los Pasivos; digamos que nuestra distribución cae como se muestra a continuación;
- Servicio Pobre [22%]
- Mesas sucias [10%]
- Opciones de menú insuficientes [10%]
- Precio [20%]
- Ubicación [20%]
Al observar los datos de manera anecdótica, podemos decir que el servicio deficiente, las mesas sucias y la ubicación son las principales razones por las que alguien será un detractor. Esto también significa que cualquier Cliente Pasivo que elija esos tres elementos probablemente sea un detractor en la próxima visita o en los próximos meses. Hay otros factores que pesan en contra de esa decisión, pero en ausencia de otros factores de contrapeso, todos los pasivos que seleccionan esas opciones son candidatos para abandonarnos.
Usamos este modelo para predecir Churn: el porcentaje de personas pasivas que seleccionan las mismas «razones» marcadas como «Predictores de Churn». Le brinda un modelo predictivo sobre quién probablemente abandonará.
Aprende más aquí: Abandono de Clientes Pasivos con NPS+ | Spreadsheet
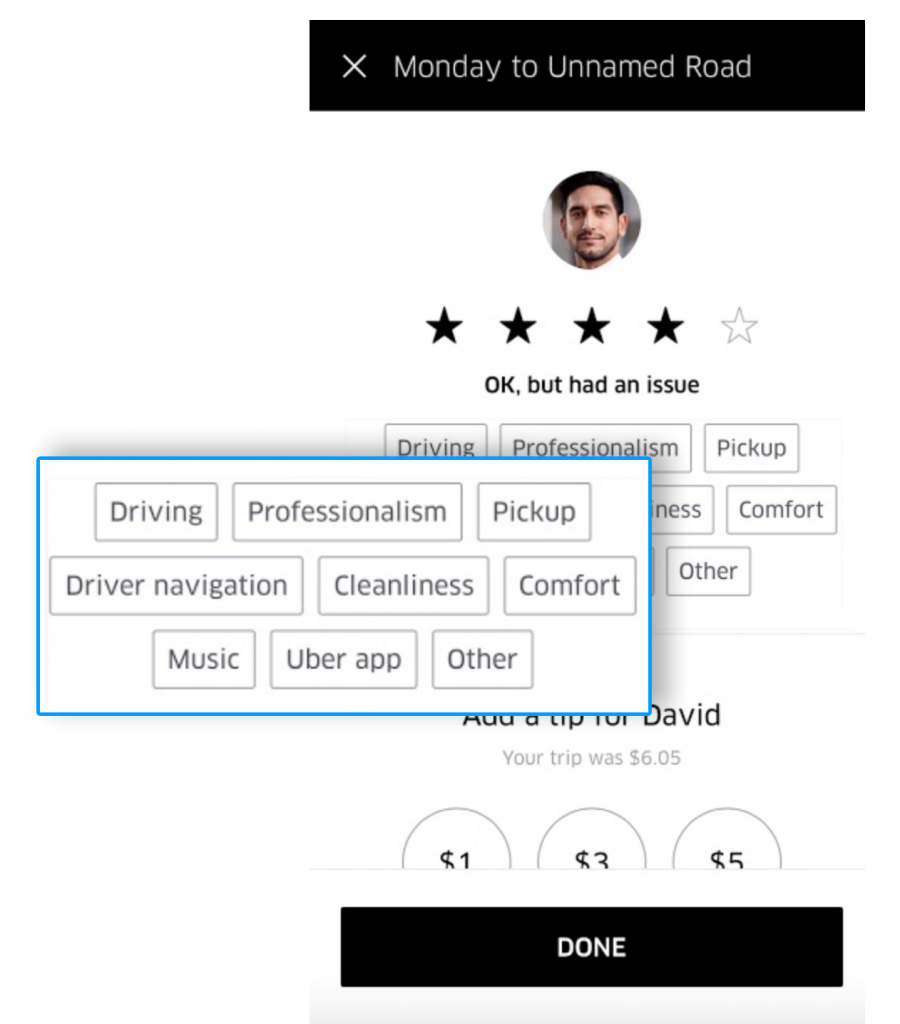
Uber: Ejemplos de identificación de Churn
Uber utiliza un modelo de identificación simplista para la identificación de la causa raíz tanto del promotor como del detractor;
Como puede ver en la captura de pantalla anterior, el usuario otorgó una calificación de 4 estrellas. Asumiendo que 3 y 4 estrellas son pasivos, Uber ahora está tratando de determinar la causa raíz de la calificación de 4 estrellas, utilizando un modelo de elección simple.
Intención declarada Vs. Intención real – Mercados saturados
Una de las premisas fundamentales en las que se basa este modelo es que los detractores tienen un riesgo de abandono muy alto. Dicho esto, se ha observado anecdóticamente que en mercados saturados como el de seguros, telecomunicaciones y otros, donde el letargo en torno a la cancelación del servicio es alto, las métricas de abandono no siempre coinciden con el abandono real. Esto se debe en parte a la incapacidad de los clientes para cambiar de solución con facilidad; los seguros son un buen ejemplo. En tales escenarios, es posible que el modelo de predicción de abandono no arroje resultados correctamente, ya que dependemos fundamentalmente de la proximidad de la intención declarada para que coincida con la intención real.
Sin embargo, creemos que es solo cuestión de tiempo que la intención declarada alcance el cambio de comportamiento real en términos de abandono. Las empresas pueden consolarse con el hecho de que, en mercados saturados, la rotación es difícil, pero dado el ritmo del cambio, está llegando.
Además, cuando la rotación se activa, en los mercados saturados, el efecto de eso es generalmente extremadamente fuerte y ninguna cantidad de medidas tácticas en ese punto puede detener la hemorragia.
Conclusión
Si bien la eficacia de NPS se ha debatido durante más de 15 años, el modelo subyacente para la segregación de clientes entre «Defensores» – «Acechadores» y «Haters» es una construcción fundamental en el modelado de satisfacción y lealtad. El modelo Churn que proponemos se basa fundamentalmente en la premisa de que los “Lurkers” pueden ser influenciados, ya sea para ser “Advocates” o no.
El modelo predictivo se basa fundamentalmente en el principio de que los clientes indiferentes son los más propensos a abandonar, de hecho, incluso más que los enemigos apasionados. Nos basamos en este precepto psicológico fundamental para modelar nuestro proceso predictivo de abandono.
Fluye hacia un almacén unificado central con conocimiento tribal mitigado y una taxonomía comercial uniforme, lo que convierte al centro de investigación en una ventanilla única para todos los conocimientos. Hay una mayor retención en la gestión y accesibilidad de los datos, lo que garantiza que no tenga que buscar en varios lugares y comunicarse con varias partes interesadas para dar sentido a los datos. Hay una mayor retención en la gestión y accesibilidad de los datos,
Análisis en tiempo real
Al usar el repositorio de información, hay acceso instantáneo y en tiempo real a datos y análisis. No solo eso, con la ayuda de etiquetas inteligentes e inteligencia artificial (IA), es posible obtener información sobre proyectos que son relevantes e interesantes. Esta característica hace que el uso del repositorio de información sea aún más lucrativo para los investigadores y las partes interesadas del negocio para aprovechar los análisis en tiempo real en la investigación de mercado amplificada y reutilizable.
