

はじめに
NPSは、CXを測定するための指標として広く用いられている。シンプルでありながら、顧客ロイヤルティ、ひいては収益性を予測する重要な尺度として注目され、世界中至る所で利用されており、多大な支持を集めている。
また「カスタマーチャーン(顧客解約件数)」は、好不調の波を乗り越えて企業を存続させることができる唯一の指標であることも分かっている。しかし、データサイエンスチームが専心的に取り組まなければ、チャーンの判断や、より重要な予測はほぼ不可能だ。大半のデータサイエンスチームは、「行動」に注目し、多くの行動変数と出口変数の相関を調べようとする。理論的には正しいのだが、これではリサーチャーに「なぜ」をもたらすことはほぼ不可能である。共関係モデルを与えるだけであり、因果関係モデルを与えるわけではないからだ。
本ホワイトペーパーでは、NPSモデルを強化し、運用的、認知的に簡単な方法を紹介する。
1.チャーンの理由(根本的原因)等の分離および特定を行う。
2.自動特定 – ダイナミックかつ自動的に理由をアップデートするためのモデルを確立する。
3.チャーン予測 – 中立者と批判者における理由特定の比較に基づいて行う。
Table of Contents
NPSプログラム – 既存のプラットフォーム/プロセス/モデルの使用
退去/解約時の調査
ほとんどのNPSプログラムでは、解約した元顧客と連絡を取り、解約理由を判断するためのモデルが用意されている。これは事後的なものであり、将来的な良い方向性を示す指標にはなるものの、運用は困難である。時代とともに理由が変化していることに加え、「ベース」となる比較対象が存在しないことも一因だ。すでに解約した顧客だけを調査しているのであれば、まだ解約していない顧客、つまり既存顧客をベースとして比較することは非常に難しい。
継続的なNPS/チェックイン調査
既存顧客に対してNPSを継続的に使用している企業は、同じモデルを使用してチャーンを判断·予測することができる。継続的な運用調査を利用して判断するメリットは、メール/SMSの通知配信、トランザクションの計上、データの収集といった機能がすでに備わっていることだ。
NPSを判断するのは容易だが、根本原因のダイナミックな判断/分離·特定は、「なぜ」を中心としたテキスト分析に委ねられている。
大概のテキスト分析モデルは、調査においてうまく作用しない。これはNLP/トレーニングデータが一因だ。優れた機械学習モデルは、精度を高めるために多くの学習データを必要とする。
本ソリューションでは、顧客自身の集合知を活用することで、「なぜ」の答えを機能的に判断していく。
分離
まずは「分離」の作業が挙げられる。分離とは、ある人が解約に傾く理由の上位1~2を判断することを意味する。すべての製品/サービスには、顧客との親和性を決定し、逆に顧客離れを決定づける、ユニークで重要な要素が存在する。ここでまず重要な考え方は、これらの重要な理由を切り分けることだ。これはテキスト分析ではなし得ないことである。単純なテキストからさまざまな理由の「重み」を判断するには、AI/NLPツールがまだ十分ではないからだ。
AI/NLPツールは将来非常に有用になると声高に宣言することに、多くのエネルギーや時間、労力を費やしてきた。しかしそれは2020年のことであり、私は未だ、自社のNLPモデルに対する信頼が十分に高いと確信を持って話すクライアントに会ったことがない。
さらにシンプルな方法を紹介しよう。NPS調査の際、顧客に一連の「理由」の中から選んでもらうのだ。以下がその例である。
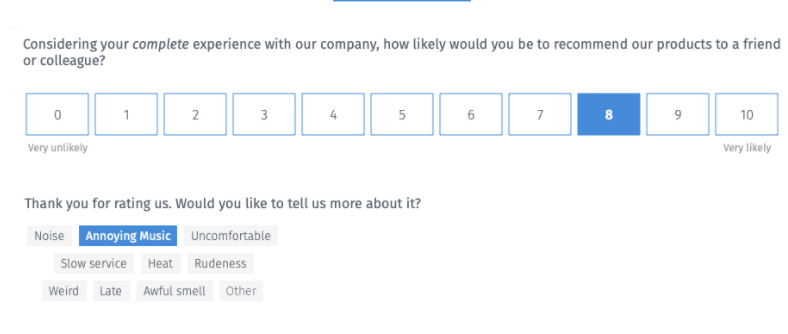
1~3項目から選択できるようにしているのは、分離のために必要だからだ。解約の理由は多岐にわたるだろうが、回答者には解約の理由の「トップ」を選んでもらうことにしている。この処理により、自動的に理由を分離することができる。
特定
次に、特定の具体例を挙げる。このように理由があらかじめ判断できているモデルを使うことに対する反論として典型的なのは、その理由が網羅的でない可能性があるということだ。これは正しい。そのため、「その他」という選択肢を用意した。NPSスコアをつけた理由を回答者自身が入力できるようになっている。
ここには、2つの重要な考え方がある。
1.コンテキストの焦点化 – 回答者には、さまざまなことを漫然と答えてほしくはない。第一の理由を特定する必要があるが、その理由は選択肢リストにはないため、自身で入力してもらう。
2.テキストの限定 – 文を1~2行に限定する(Twitterの140文字と同程度)ことで、顧客の注意を集中させ、根本原因を突き止められることが分かっている。また、センチメント分析とは異なり、トピックの特定も可能である。すでにNPSは分かっているので、もはやセンチメント分析は必要ない。ここで重要なのは、トピックを正確に特定することだ。
さらにデータ/コンテンツディクショナリーを使い、NLP/テキストモデルで「トピック」を決定する。この場合も、ユーザーが入力しなければならない「トピック」、つまり「サーバーが粗野だった」「選択肢が少ない」といった言葉のみを探して、トピックの自動特定のためにモデル化している。このほうが遙かに正確だろう。
トピック発見のためのAI/ML
QuestionProはBryght.aiと提携し、AI/MLモデルをトピック特定に使用する予定である。

その理由には、Bryght.aiのチームと協力して、ゲーム、小売、ギグエコノミー、B2B SaaSなど、複数かつユニークな垂直分野でのデータディクショナリーを開発したことがある。これらのカスタマイズされたデータディクショナリーは、業界知識をベースに、より精度の高い、フォーカスされたデータを提供する。
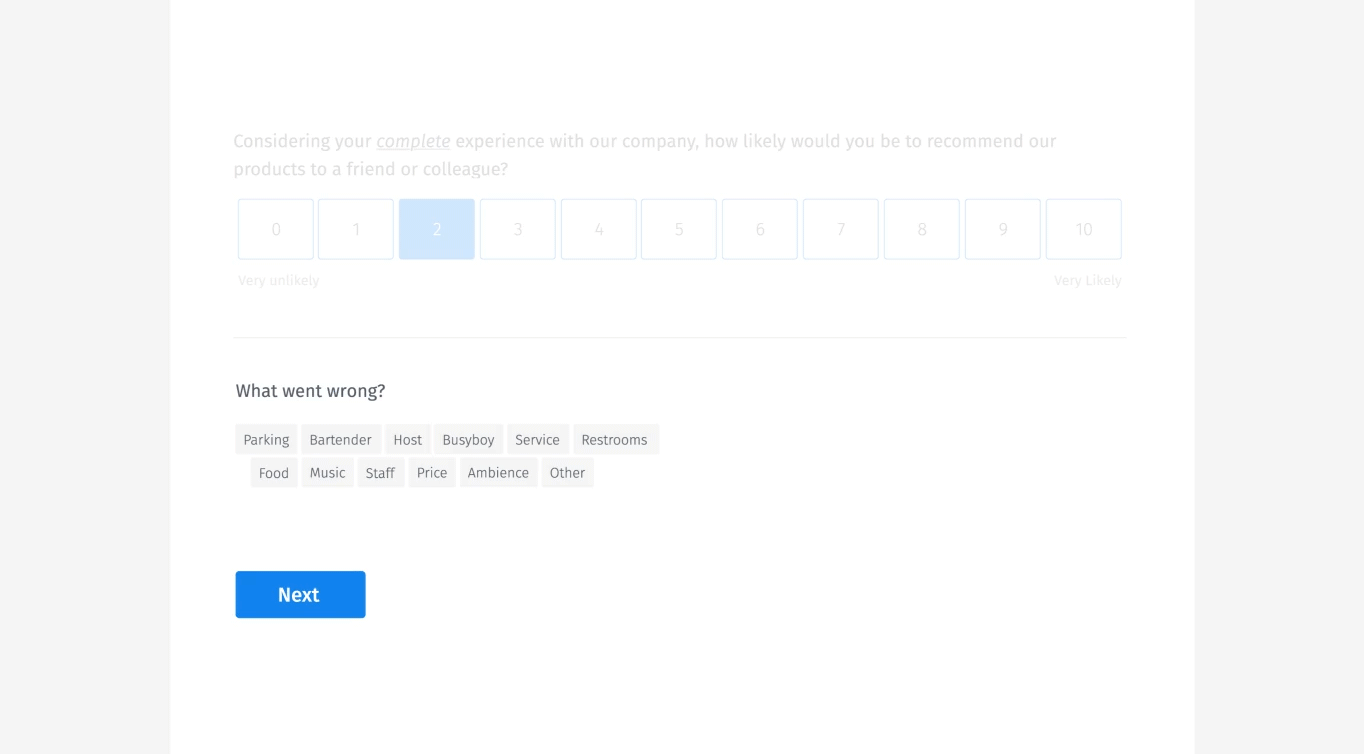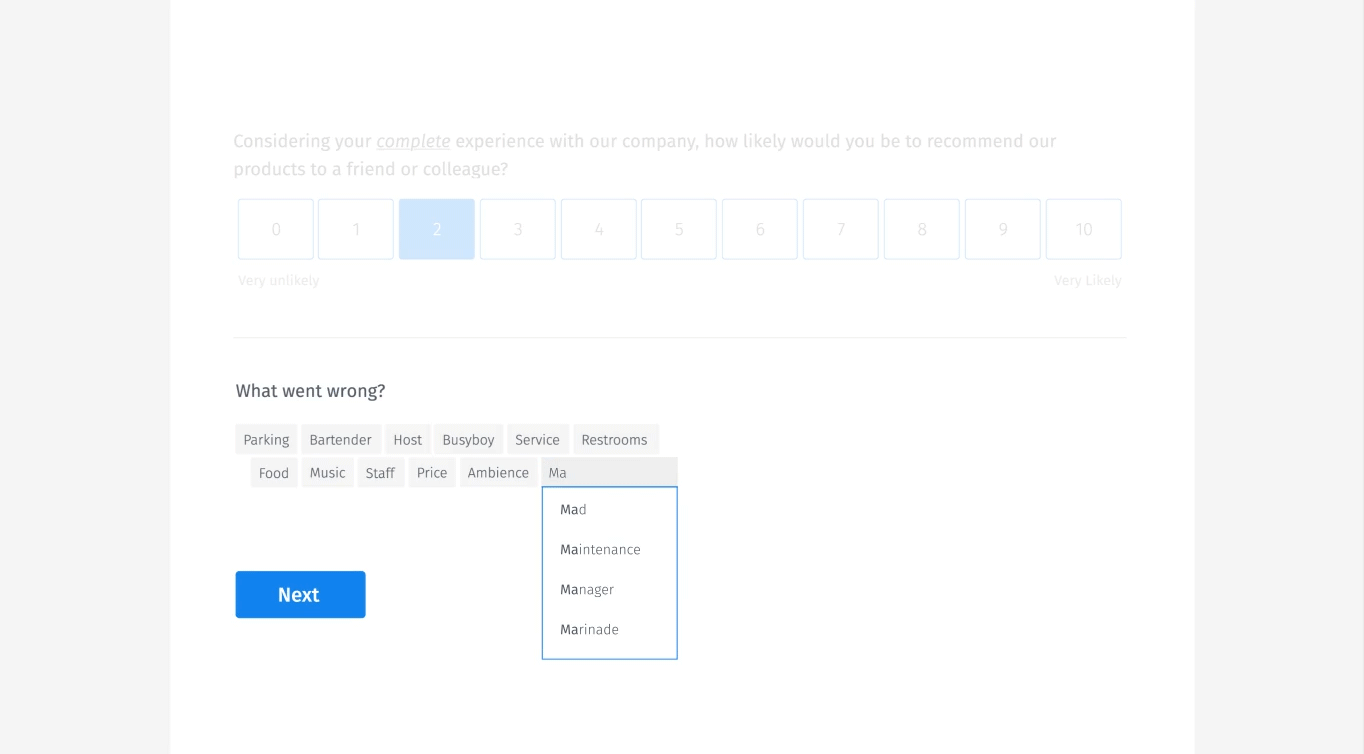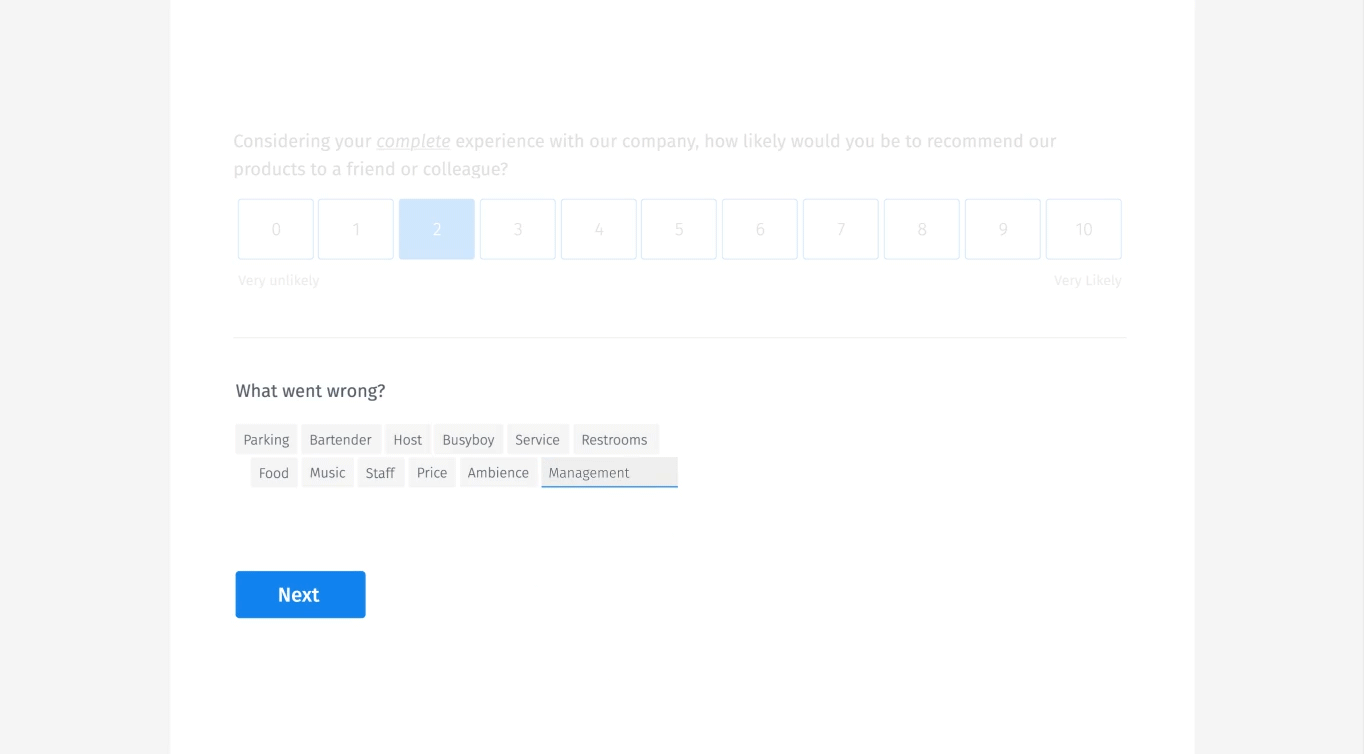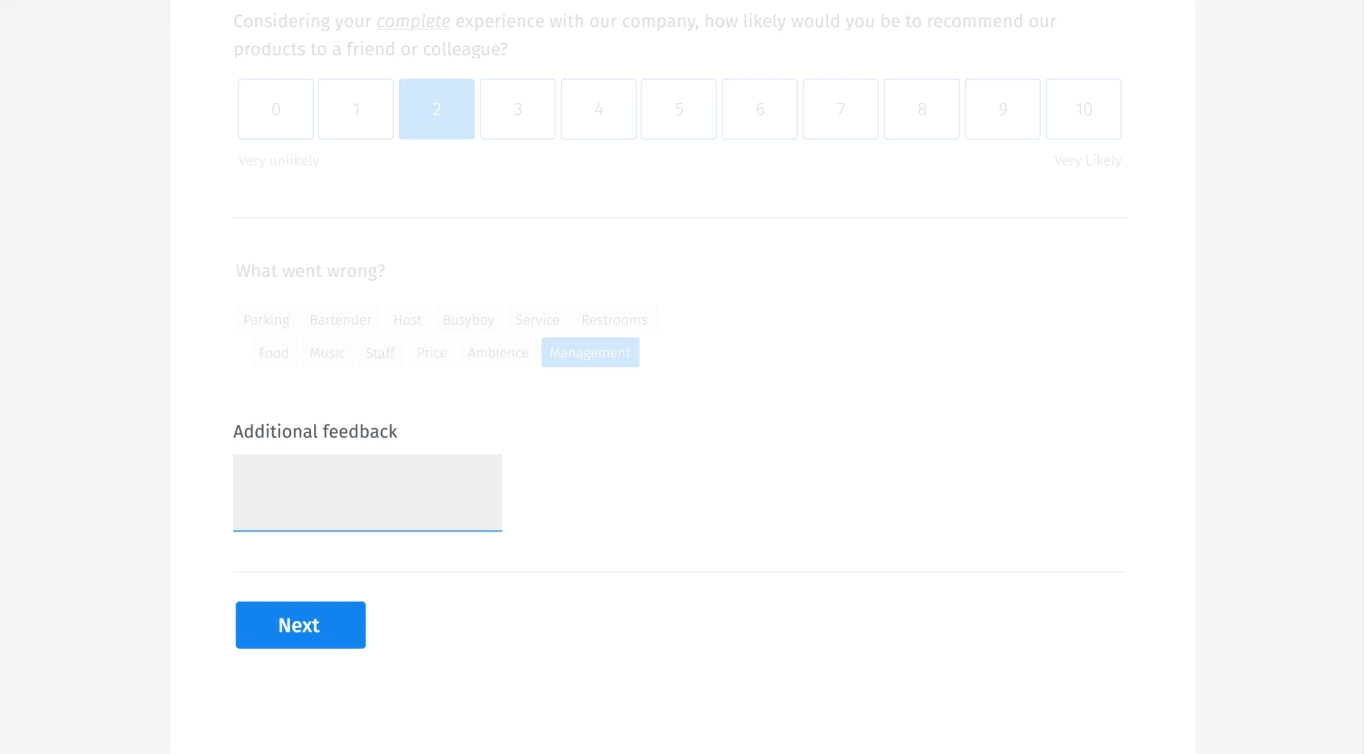
予測型サジェスト
また、Googleサジェストによく似た予測型のサジェストも行っている。ユーザーが入力する際に、他の人が提案したものを表示するのだ。これにより、ユーザーはデータディクショナリーを指数関数的に拡張するのではなく、単に項目を選択することができる。
上に実例をビジュアルで紹介している。
予測
これまでのところ、上記の特定&分離モデルで、a·b·cは人々が不満を抱いて批判者となる理由のトップである。したがって、彼らはすべて100%のチャーン傾向を持っているという仮定を決定論的に述べることができる。解約の理由を特定·分離するために、批判者を利用することは論理的である。批判者はすでに解約しているものと思われ、現時点ではそれを防ぐことはほぼ不可能だろう。
中立者たちは「未決定」であり、現時点では揺らいでいるが、どちらにも傾く可能性がある。予測モデルでは、さらに中立者に、批判者に与えられた理由と全く同じものを選んでもらう。これにより、中立者と批判者を比較し、解約しそうな中立的な人々を正確に特定し、予測することができる。
実例を挙げて説明しよう。批判者が選んだ理由が5つあるとする。
·サービスが悪い [80%]
·テーブルが汚い [30%]
·メニューが少ない [18%]
·価格が高い [12%]
·立地が悪い [21%]
批判的な理由を3つまで選択できるようにしたため、合計値は100にならない。上記のように、この分離モデルは、1~3(上位1つ、または2つの理由を選んでもらう)のいずれかになる。
中立者は、例えば次のような分布になるとする。
·サービスが悪い [22%]
·テーブルが汚い [10%]
·メニューが少ない [10%]
·価格が高い [20%]
·立地が悪い [20%]
データから推測すると、「サービスが悪い」「テーブルが汚い」「立地が悪い」などが、批判者となる理由の上位に挙げられている。これは、この3項目を選んだ中立者は、次回訪問時や数ヵ月後に批判者になる可能性が高いということでもある。他の要因もあるが、他に相殺する要因がない限り、これらの選択肢を選んだ中立者はすべて解約の候補となる。
このモデルを使って、チャーンを予測していく。「解約予測因子」としてマークされたのと同じ「理由」を選択した中立者の割合を算出する。これによって、誰が解約するのかを予測することができる。
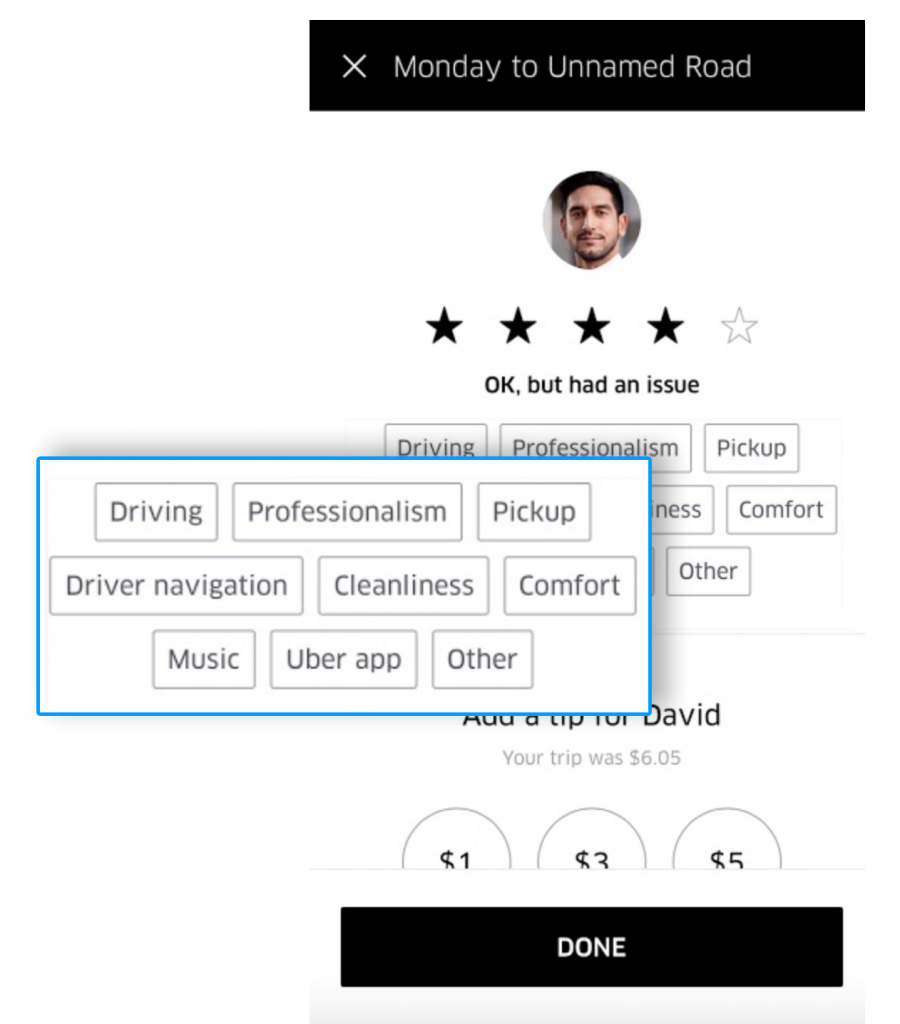
Uber:チャーン特定の実例
Uberは推奨者(Promoter)と批判者の双方の根本原因の特定に、単純化された特定モデルを使用している。
スクリーンショットから分かるように、ユーザーは星4つの評価をした。星3つと星4つは中立者であると仮定し、Uberは単純な選択モデルを使用して、星4つの評価となった根本原因を判断しようとしている。
回答結果 VS.実際の意図 – 飽和市場
このモデルが依拠する大前提の一つは、批判者は確かに極めて高い解約リスクを持っているということである。しかし、保険や通信などの飽和市場では、解約に対する抵抗感が強く、チャーンの指標は必ずしも実際の解約件数と一致しないことが指摘されている。これは保険を例に挙げれば分かるとおり、顧客が簡単にソリューションを切り替えられないことが一因だ。このような場合、チャーン予測モデルは、基本的に表明された意図と実際の意図の近さに依存しているため、正しい結果を得られない可能性がある。
しかし、表明された意図が実際の行動変化に追いつくのは、チャーンの観点では時間の問題だ。飽和市場の商品を解約するのは困難ではあるが、それでも変化のペースを考えるとチャーンは起こり得るのだという事実を、企業は慰めにすることができる。
さらに、飽和市場においてひとたび始まったチャーンの影響は一般的に極めて強く、その時点でいくら戦術的な対策を講じても、流出を止めることはできない。
結論
NPSの有効性については15年以上前から議論されているが、顧客を「支持者」、「潜伏者」、「嫌悪者」に峻別する基本モデルは、満足度とロイヤルティのモデル化において基礎的な構成要素となっている。私たちが提案するチャーンモデリングは根幹的に、「潜伏者」が「支持者」になるかどうかが前提となっている。
この予測モデルは、基本的に無関心な顧客が最も解約しやすいという原則に依拠しており、実際、熱心な嫌悪者よりも高い確率で解約している。私たちは、この基礎的な心理的教訓をもとに、チャーン予測モデルを確立している。
データは、トライバルナレッジを緩和し、ビジネス·タクソノミーを統一した統合ウェアハウスに流れ込む。これにより、リサーチハブはあらゆるインサイトをワンストップで提供することができる。データの管理およびアクセス性をより重視することで、データの意味を理解するために複数の場所を調べたり、さまざまなステークホルダーに連絡を取ったりする必要がなくなり、多変量リサーチデータの管理も容易になる。
リアルタイム分析
インサイトリポジトリを使用することで、データや分析に瞬時かつリアルタイムでアクセスできる。それだけでなく、インテリジェントラベルや人工知能(AI)の力を借りれば、関連性の高い、興味深いプロジェクトの情報を浮上させることが可能だ。この機能により、リサーチャーやビジネスステークホルダーがインサイトリポジトリを利用し、増幅·再利用可能な市場調査においてリアルタイム分析を活用することが、より一層有利となる。
