

Executive Summary
Over the last few years, companies have recognized that research, not limited to Product, Consumer, and UX, has become its own strategic asset. High performing companies have come to realize that research can provide the competitive advantage and differentiator factor. This has led many companies to building internal functions, capabilities, and departments at scale around research.
Internal research teams then act as a service provider to the various parts of the larger business. Most research teams have a constant inbound stream of “Asks” from various business units and more importantly, they are constantly being asked if there is some existing research around specific functions or business areas.
We propose that research teams should think of an insight repository with a business focused taxonomy that creates a knowledge base that can be indexed, searched and repurposed with the end goal of democratizing access to insights.
The primary benefit of an insights repository is to build upon the research and insights of those who have come before. There is no need to reinvent the wheel every time. Every company invests in a CRM that acts as the single source of truth regarding customer intel. The same applies to technology/software – where source code – acts as the ultimate source of truth, stored in a repository that is traceable and structured. This format and system architecture can be applied to research functions and infrastructure. We propose that research teams take a page out of the CRM or Engineering playbooks and create for themselves a single source of truth.
This article is also available in audio.
- Executive Summary
- Insights Repository
- What is a repository?
- What are the key elements of data that an insights repository should have?
- 1. Insights / Themes / Stories
- 2. Observations and nuggetted information
- 3. Raw research data & evidence
- 5 Characteristics of an insights repository
- Primary Benefits of having an insights repository
- Efficient and reusable workflows
- Quick & self-service access to insights
- Enhanced knowledge access and graph
- Added transparency and no loss of information
- Quick turnaround studies
- Democratized data & unified warehousing
- Real-time analytics
- Business Need & ROI of Insights / Research Repositories
- Research and the data is extremely siloed
- The same research is conducted multiple times
- Research reports go unnoticed
- Workflows are arbitrary
- Knowledge discovery is non-existent
- Proving the ROI of research
- The Business Taxonomy
- Nodes, Metadata, Tagging & Attributes – A fresh approach to Organizing
- Workflows
- Operational & Execution Challenges
- Leadership buy-in and alignment
- Researcher Education
- External Research Vendors
- Fragmentation of Repositories
- Maturity
- Method to create and manage an insights repository with steps
- 1. Appoint the team to manage the insights repository
- 2. Organize your existing and past research
- 3. Add supporting insights & evidence
- 4. Synthesize and analyze data
- 5. Create critical insights, findings, and reports
- 6. Tag and share insights
- Authors
Insights Repository
What is a repository?
“Is any platform, system, drive, database, content collaboration tool, library, knowledge base, wiki, or file cabinet that stores research data, notes, transcripts, images, videos, recordings, findings, insights, reports, metadata, etc. to support consumption and reuse by the entire team.”
— Research Repositories Workshops in 2020, A Research Ops Community project
We want to extend this definition further by noting that the key difference between a repository and archival files is three-fold:
- Content is indexed and easily searchable, accessible & browsable
- There is a chronological element to the data
- The team accepts it as a definitive & authoritative source
In other words, an insights repository is defined as a central source of truth that researchers and relevant stakeholders can access the research that an organization has conducted, both past and present. Having a consolidated platform to organize, explore, search and discover all the research data of a company in one organized location.
What are the key elements of data that an insights repository should have?
The insights repository consists of three fundamental levels of data:
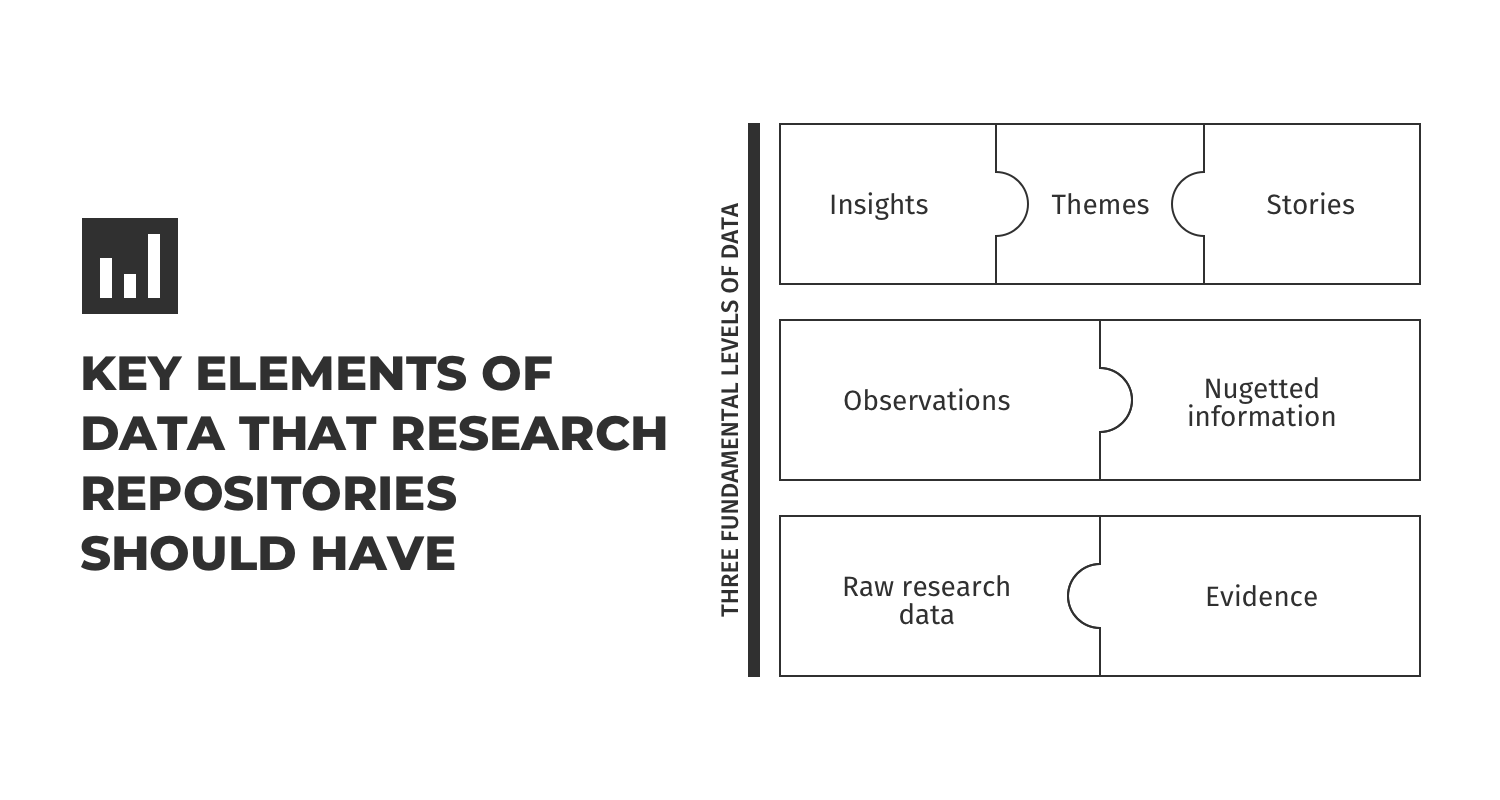
1. Insights / Themes / Stories
At a holistic level, the insight repository consists of tagged, indexed, and unified insights. This is from past and existing studies of different research types, including qualitative and quantitative studies, user research, custom studies, advanced research modeling studies, and more. All of these insights are easily searchable with the use of business taxonomy and meta-tags. These insights also monitor cost spends, ROI of studies, and other factors that provide an insight into time and resource spends.
2. Observations and nuggetted information
The secondary level of an insights repository aims to provide information at an even more granular level of studies a certain team or product conducts, insights from longitudinal tracking studies, product enhancements, marketing messaging, or a campaign that emanated from a given initiative. This level also stores presentations and outcomes so that tribal knowledge from siloed studies is available for all to see.
3. Raw research data & evidence
The final component of this repository is the actual data, including customer calls, vendor research data, questionnaires, business taxonomy tagged studies, qualitative and quantitative data, IDI’s, customer behavioral data, and more. All of this is unfiltered data that can be looked upon and leveraged when needed.
5 Characteristics of an insights repository
After speaking to multiple researchers, business stakeholders, and companies that have implemented some version of an insights repository, we have identified the five most important aspects.
These key characteristics would lead to widespread adoption and use and acting as a cornerstone and guidebook for successful research repositories.

1. Retrievable
An essential characteristic of an insights repository is that it needs to be very easy to access researchers and other business stakeholders alike. Team members should quickly get their hands on information easier to understand and consume without writing multiple queries on varied platforms. Putting all of this information together in one single platform is critical. Researchers should be able to pull up information from past studies to support their ongoing studies or keep them from doing a study all over again. Business stakeholders should also be able to pull up insights based on what is important to them, including demographic information, project costs, longitudinal research studies, and more.
2. Approachable
All the relevant stakeholders in a business should want to leverage the insights repository for their information gathering. The tool should be easily approachable to members at all levels so that the tool’s adoption is high. It should also be effortless to draw analysis while avoiding complicated and clunky workflows. Stakeholders like to have access to data that is powerful but easily represented and lightweight and not have to look at complex reports and charts.
3. Traceable
A successful insights repository shouldn’t be just beautiful charts and numbers without ever linking back to data. Being able to marry insights to data is crucial. Creating a way to connect back to the origin data if needed is a must have. There has to be a reference to the original or raw data that builds confidence as it is evidence-based. The insights repository should link back to all of the data even from years ago if it needs to be validated or even check if inferences made at the time hold today. Easily traceable data also ensures that multivariate data still makes sense in the case of repeat studies or longitudinal tracking. Lastly, with traceable data, researchers should draw new conclusions and insights just as quickly.
We believe there are two key elements here:
- Timestamp
- Data Source & Evidence
Every element should be time stamped – Insights and data changes fast and items have a shelf life. The same applies to connecting insights to raw data or evidence. This allows us to build confidence in the insights with traceability and accountability back to the source or the raw data.
4. Accessible
For an insights repository to have high adoption rates and make a difference, it needs to be accessible to all the relevant stakeholders. Even newcomers in the research teams should have access from day one to go in and make informed decisions and inferences about past studies without losing time. For tremendous success, the adoption of the tool should be immediate and constant. Your insights repository should be the single source of truth, and team members should not have to look at various folders, reports, documents, and spreadsheets to uncover insights.
5. Secure
As your insights repository will house data from multiple sources and is a single source of truth for your organization, it’s likely to house information that can be confidential and sensitive. For your insights repository to have widespread use across global organizations, the tool must meet guidelines of federal and other local government mandates of data warehousing and security like being GDPR compliant and more. There also have to be policies in place for the retention, encryption, anonymity, and deletion of data.
Primary Benefits of having an insights repository
An insights repository consists of multiple moving parts that make researchers’ and organizations’ lives better and efficient. Some of its significant benefits and advantages include:
- Democratize access to insights. Anytime, anywhere, on demand.
- Reduce reliance on humans and tribal knowledge.
- Enable researchers to re-use and build upon existing knowledge and research.
Efficient and reusable workflows
Using an insights repository helps put together new project intake processes, managing projects, status updates, templates, etc., which have all been traditionally cumbersome and inefficient for insights professionals. With the set-up of workflows of how the data flows right from a requisition phase to the insights being tagged and monitored in the user insights repository, a clearly defined structure is a significant time and resources saver.
Quick & self-service access to insights
After completing research studies, there is a meaningful and searchable repository of data, key findings, and materials of all projects. It now becomes advantageous and straightforward for researchers, insights teams, and stakeholders to look up current or past data in one unified platform that provides rapid access to insights.
Enhanced knowledge access and graph
Building on past research that has already been conducted instead of starting from scratch enhances the knowledge access and graph. It is effortless to gain knowledge on past studies and build trendlines of past discoveries with current existing gaps. Since collective knowledge is pooled together, there is constant internal continued discovery on nuggets of wisdom, cost rollups to show ROI, and more, easily.
Added transparency and no loss of information
An added advantage of this knowledge hub is that there is added transparency in the research design and process right from someone requesting research to the teams that conduct them and publish reports. It is also easy to locate studies that were previously conducted, and the team members involved, so it’s then easy to pull information based on various criteria.
Quick turnaround studies
Access to information such as types of studies, questionnaires, tools used, survey respondents, and more aids in conducting quick turnaround studies where many administrative aspects are already known to the researchers and other relevant stakeholders. This allows in leveraging past intelligence and deploying faster studies that provide actionable insights faster.
Democratized data & unified warehousing
The data from across teams and business units flows into a central unified warehouse with mitigated tribal knowledge and uniform business taxonomy, making the research hub a one-stop-shop for everything insights. There is a greater hold on data management and accessibility, ensuring that you do not have to look in multiple places and reach out to various stakeholders to make sense of data. In this case, it also becomes simpler to manage multivariate research data.
Real-time analytics
By using the insights repository, there is instant and real-time access to data and analytics. Not just that, with the help of intelligent labels and artificial intelligence (AI), it is possible to surface information about projects that are relevant and interesting. This feature makes using the insights repository even more lucrative for researchers and business stakeholders to leverage real-time analytics in amplified and reusable market research.
Business Need & ROI of Insights / Research Repositories
There is now a structure to understand why there is a business need for an insights repository but the actual causes that necessitated expediting such a solution. Broadly, research falls under two buckets – generative research that aims to unlock opportunities for brands and evaluative research that tests certain use cases and solutions.
There is a fundamental dereliction of knowledge management and scalable insights at the heart of both these insights use cases. Traditionally, there have been issues of digging into past data, bringing new members up to speed, leveraging past research, knowledge being lost in individual studies, tribal knowledge, and more. To make the process of insights scalable, businesses and organizations need to tide over these specific issues.
The most prominent problems that necessitated the need for an insights repository are:
Research and the data is extremely siloed
Organizations conduct research at various frequencies, scales, and complexities. Different groups within an organization may conduct research themselves or send it to specialized researchers who then run studies. Most companies have a mix of outsourcing and in-sourced research – and this leads to different systems of record and classification of research.
Add to this the variable factors of research among other divisions, business units, and geographical locations with different types of studies. Think about customer studies, usability research, online focus groups, quantitative research, and then the mounds of survey data collected. All of these find their way into small groups but are never democratized. The research data is highly siloed, and there is no way for anyone to make sense of this data after a specific period. Even if this data is chanced upon, there is a lot of tribal knowledge in the data that it’s challenging to make sense of.
The same research is conducted multiple times
Another major factor that caused the need for the birth of research repositories is the number of times the same research is conducted. More often than not, when new members join teams, they go off and run studies that have already been completed before and draw insights that have been collected before. This contributes to the loss of time and money and reduces the ROI of insights – by increased duplication efforts. More often than not, business stakeholders get wary of the insights that researchers send them. With time, since the research and data echo similar sentiments, it takes away credibility from researchers and the research reports.
Research reports go unnoticed
Research reports are produced at the end of each study, but unfortunately, there is little to no structure on how these are produced, stored, or distributed. Add to this the complexity of how researchers construe data, and the non-alignment of insights to business problems lead to these reports being buried. More often than not, these reports are also hard to find since they live in various places and, over time, become obsolete. Another issue with reports is that there is no data-driven structure to findings or recommendations, leading to a higher level of distrust among stakeholders.
Workflows are arbitrary
Large complex organizations have no insight into research conducted at a larger scale and the stakeholders involved purely due to the complexity of the data collected. Besides, various stakeholders look at business problems differently and may ask for various insights for similar studies. Project intake forms vary from person to person, and research methods are also varied. Thereby, each workflow becomes exceptionally arbitrary, and thereby, making sense of processes after a particular time becomes highly complex.
Knowledge discovery is non-existent
Each of the research projects has a reason. Research and research surveys are done for specific needs – brand, customer churn, etc., where these business taxonomies are typically captured in conversations, email and tribal knowledge. Traditionally, there was no way to set up business taxonomies and set up meta tags to research studies to pull insights from. Even new members do not have transparency into past studies and the findings and learnings of past studies in one centralized repository.
Existing market and tools are fragmented
One of the biggest challenges that warranted an insights repository is that the existing market and tools are highly fragmented. Add to the complexity of various solutions, softwares, current tech stacks, and communication and management tools. It is a mix of multiple levels of conversations and interactions across various levels. There are some tools to requisition studies, project management tools, software to manage studies, research reports, and more. Not just this, there are internal communication tools, and then communication with vendors, their APIs, etc., adds to the complexity of the flow and management of knowledge.
Proving the ROI of research
Due to the fragmented nature of these tools, research cycles become longer and complicated. Other factors lead to the complexity of research and can bias with the questionnaires used, vendors used, respondent sample reached out to, the tools involved, and more. Due to this, most critical research studies take a very long time from conception to actionable insights phase while still applying a layer of complexity and uncertainty. Thereby, when decisions are taken, it is challenging to tie the research process to the actual end factor and makes it tough to justify the ROI of research.
These factors contributed to the need to put together a system that makes the research and insights process simpler, efficient, and faster.
The Business Taxonomy
Nodes, Metadata, Tagging & Attributes – A fresh approach to Organizing
We believe it’s critical to have a future-proof and flexible way of organizing projects as well as insights – so that, as the business grows and changes – the flexibility to reorienting the taxonomy is dynamic. This means using “Tags” instead of rigid categories and creating a flexible knowledge graph of insights.
Tags & Attributes associated with Insights have to be dynamic and flexible – where new tags/concepts can be introduced anytime and older tags are sunset without substantially affecting the data model.
We also believe that tags/concepts need to be nested and hierarchical. This allows for a more natural node and tree categorization model – that accurately represents the real world.
Workflows
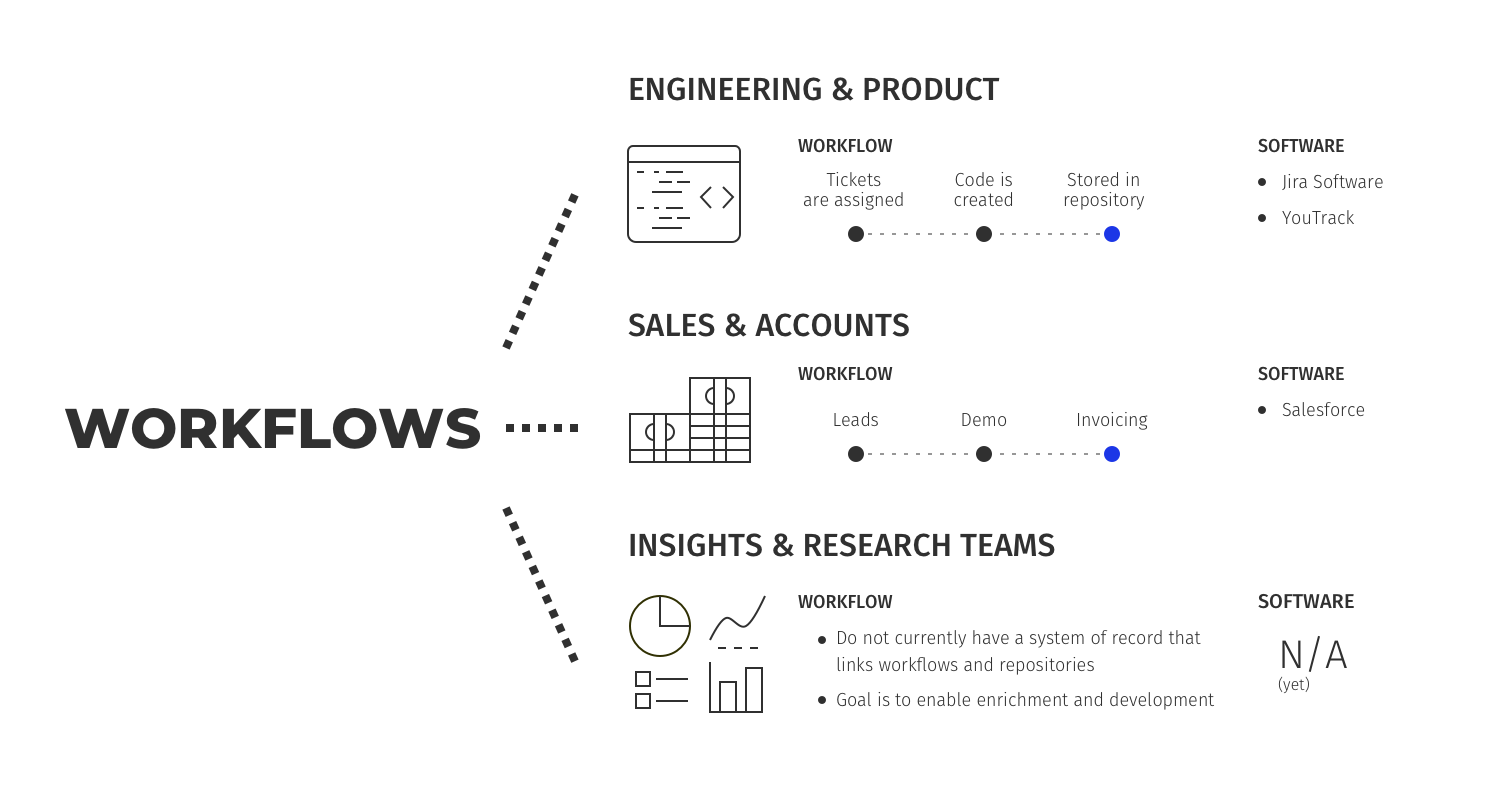
Let’s take a look at how engineering & product teams function in a fast paced environment. They all use some sort of a ticketing system/bug/issue tracking system to manage their workflows. Assignment, ownership and status are managed there. Jira, YouTrack et al. Code is written and stored in source code repositories and consequential updates and builds are linked to tickets. There is a virtuous cycle of integration between the workflows and repositories and output (builds)
Let’s also look at sales and account teams – they use CRM platforms for storing customer data as well as a connected set of tools that define workflows. Sales->Demo->Invoicing. With the App Marketplace, Salesforce has built a dominant position by enabling various workflows on top of the CRM/Repository data.
Designing a repository model, without integrating this into existing workflows or enabling existing workflows to add to the repository would be counterproductive. Just like how small sales and engineering teams – initially start off with a spreadsheet and eventually migrate to a system of record – like Salesforce or Jira – Insights & research teams need to have a system of record for defining their workflows and have a deep interlinking between the workflows and the repositories. In other words, workflow tools enable the enrichment and development of the repository.
Operational & Execution Challenges
As teams have rolled out research repositories in various companies, we’ve done 1-1 interviews with about 10 companies and identified a few challenges that most of them faced.
Leadership buy-in and alignment
As with most initiatives, leadership must see the economic benefit and the ROI for instituting such a process / system. Without their underlying buy-in – intellectually such initiatives are destined to fail. A lot of our research showed that leaders are willing to experiment with such ideas and gradually prove the ROI in their own context. This allows for an easier model to convince leadership to pilot such a system with one team or a subsection of a team and determine efficacy and then make a decision.
Researcher Education
We have to educate/empower and demand researchers to follow some basic guidelines around tagging, nomenclature and organization. Just like salespeople have to be cajoled to put data into the CRM in an organized manner, where there is sales training, we anticipate that researchers need to be walked through this process – of collating the data and organizing and reporting on it in a structured manner. Magically expecting a tool or a platform to solve human behavior change, without training and diligence will be counterproductive.
External Research Vendors
External vendors post an interesting challenge when it comes to taxonomy and following guidelines. It also poses challenges in terms of access and contributing easily into the repository. Do we allow vendors to access the system repository or have data passed through a data/governance process?
Fragmentation of Repositories
As in a complex environment, fragmentation of data and process, including repositories is bound to happen. Silos’ are created with vendors, teams and even within teams technology limitations create silos. Research teams may not want to let go of their control over the data and the narrative.
Maturity
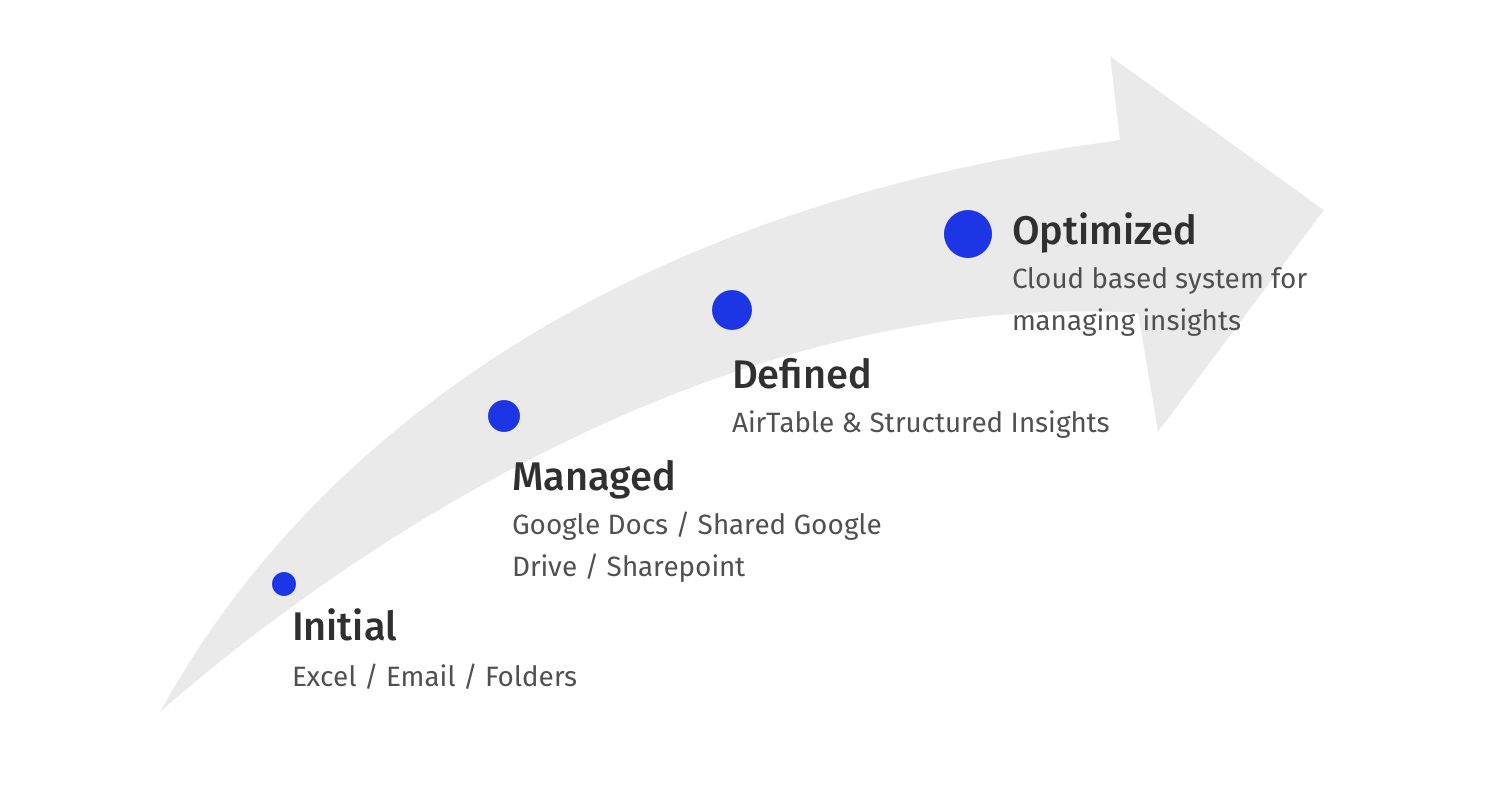
Many companies start off with simple tools and folders to manage insights. These can vary from an organized folder in the researcher’s desktop to a shared google drive or sharepoint folder where all the researchers contribute files and data to.
Maturity Scale & Levels
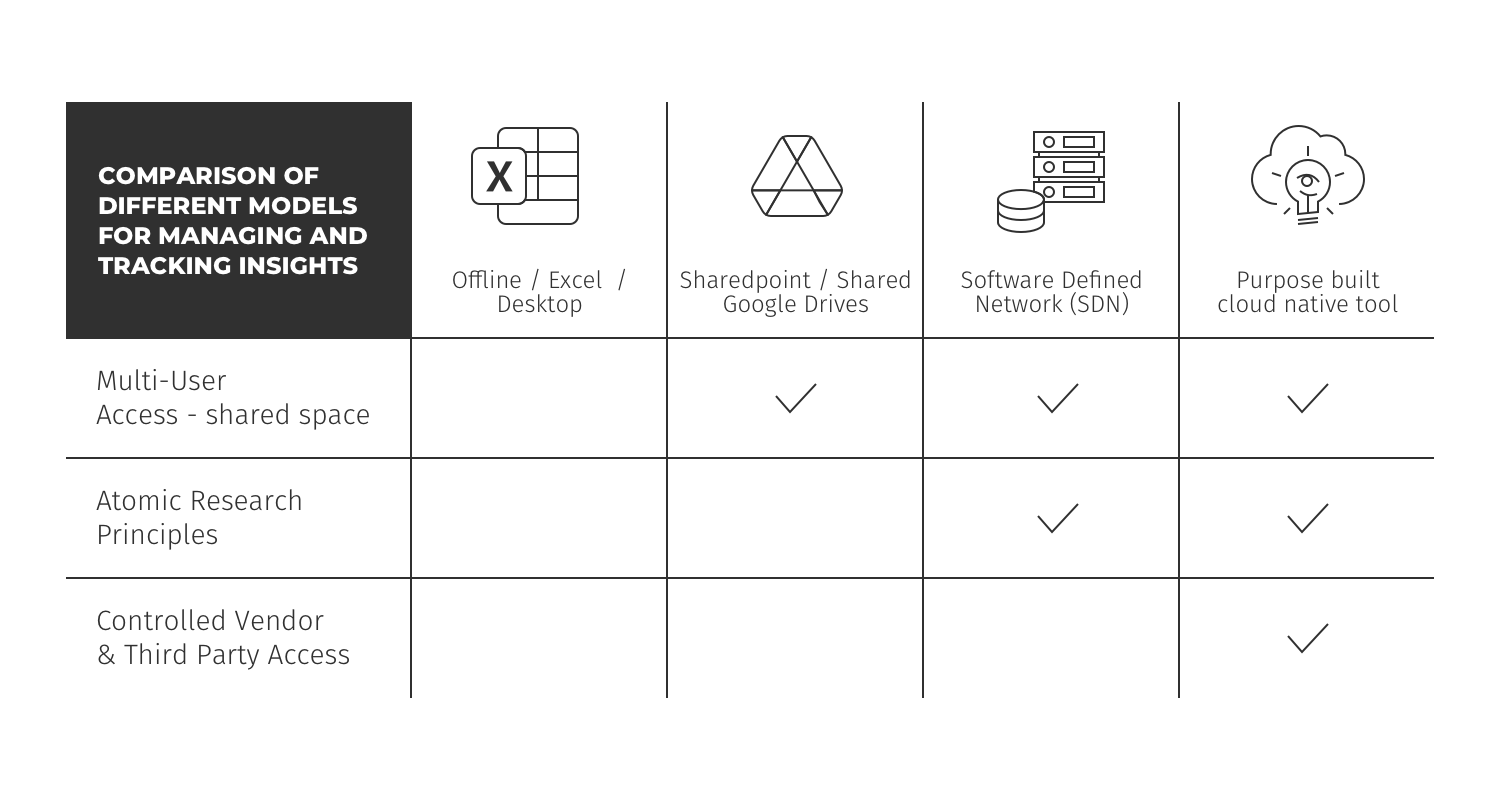
The table below describes the pros/cons of the different models for managing and tracking insights;
Method to create and manage an insights repository with steps
If appropriately managed, the adoption of an insights repository at an organizational level is very high. This user insights repository can also solve research problems at macro and micro levels and be an instrumental facilitator in uncovering and managing actionable insights. But to be able to do all of these things, there has to be extreme clarity from all stakeholders on current processes and the things they need to get to a unified research and insights platform that is scalable and provides value. It would help if you also thought through your existing technology stack used for research and collaboration, vendors and vendor APIs, existing knowledge management hubs, workflows, and other internal factors before deciding on the platform.
Here is the method to create and manage an insights repository in six easy steps:
1. Appoint the team to manage the insights repository
The researchers and the broad-based research team in your organization should maintain and own the insights repository. Even within the group, appoint leaders and research champions that will drive adoption of the tool internally and across the organization. Such a team and its members need to have an overarching view of the research conducted across the organization and with various internal and external stakeholders. This team should also be responsible for managing the taxonomy, setting up workflows, and helping derive knowledge from the insights hub. Tasking this team with increasing adoption across the organization helps make this platform the single source of truth and information across the organization. While multiple members can contribute and contribute to this platform’s adoption and success, there must be business leaders that can fully unlock its potential.
A simple metric to measure success would be the number of users, stakeholders who consume information from the repository on a monthly basis. Any system should be able to track this and report on it – for internal accountability.
2. Organize your existing and past research
Once you have decided on the team and the tool, it is vital to define the business taxonomy, a grouping of tags, and more to organize existing and past research. This could either be by projects, products, locations, or any other criteria of your choice. The proper organization helps consolidate research and insights from varied sources and immediately build a robust and scalable knowledge graph. Not just that, business stakeholders and researchers across the organization then get insights into the volume, scale, methods, tools, and the ROI of research.
An added benefit to building your taxonomy upfront – is to build details even within the insights and research teams about a shared sense of what is important and how we have a common view of the business.
3. Add supporting insights & evidence
By adding notes, data, observation, and feedback, you can make the insights repository extraordinarily robust and powerful. Putting together relevant information and then tagging them in a manner that works best for your brand allows you to get the most concrete and precise insights needed by teams at large. It may feel like adding too much information, but if it is tagged correctly with all of the relevant insights and data, you create the most potent version of your insights repository. With the addition of best practices, notes, and other supporting information, your research hub will continue to grow, and the time to derive actionable insights will be reduced.
We also suggest that having the ability to “drill down” into the evidence is critical. Even screenshots of evidence is much better than having no linkage between insights and evidence. Think of this as the “references” section in a journal. Those footnotes and references keep all of us honest and allow for public scrutiny of the finished product.
4. Synthesize and analyze data
Using a tool that allows you to manage your research data – both qualitative and quantitative and their analysis in one platform, you are getting the best of both worlds – product management, research platform, and communication tools in a centralized location. This also allows the ability to bring all the relevant data in one centralized location to manage better and even access later if required.
Consider using API’s to link insights and reports to raw findings and evidence. Almost all vendors have open API’s to for systems to interact with each other.
5. Create critical insights, findings, and reports
It is imperative to create easily digestible reports and nuggets of information in your research hub. Cutting down complex studies into smart-tagged reports consisting of critical insights and findings would offer the best adoption for the repository. Not only this, these findings provide a snapshot view of each report and then give the ability to compare reports, draw conclusions, identify cost roll-ups and justify the ROI of research. By creating a snapshot view of each research study by name, requestor, business unit, research methodology, timelines, costs, and more offers the most concrete information about the platform and thereby increases adoption.
6. Tag and share insights
Lastly, tagging research studies with the proper business taxonomy and meta-tags help group, index, and create searchable insights reports. Grouping or adding multiple tags isn’t an issue as long as they can help draw immediate inferences. Tagging and sharing insights provide stakeholders an insight into the research process. This also aids with increasing the adoption and use. The groupings may have overlapping insights, but that’s fine for all the relevant stakeholders as per job, research study, business group, and more get access to the insights.

