

Resumen
A través de los últimos años, múltiples empresas han reconocido que la investigación se ha convertido en su más importante activo estratégico, y ya no solo está limitado al producto, consumidor o UX. Las empresas de alto rendimiento se han dado cuenta de que la investigación puede proporcionar una ventaja competitiva y un factor diferenciador. Esto ha llevado a muchas empresas a desarrollar funciones internas, capacidades y departamentos a escala en torno a la investigación.
Los equipos de investigación internos actúan como proveedores de servicios para las diversas partes del negocio más grande. La mayoría de los equipos de investigación tienen un flujo de entrada constante de «Preguntas» de varias unidades comerciales y, lo que es más importante, se les pregunta constantemente si existe alguna investigación existente sobre funciones o áreas comerciales específicas.
Proponemos que los equipos de investigación piensen en un repositorio de conocimientos con una taxonomía centrada en el negocio que cree una base de conocimientos que se pueda indexar, buscar y reutilizar con el objetivo final de democratizar el acceso a los insights.
El beneficio principal de un repositorio de conocimientos es aprovechar la investigación y los conocimientos de quienes lo han precedido. No hay necesidad de reinventar la rueda cada vez. Todas las empresas invierten en un CRM que actúa como la única fuente de verdad con respecto a la información del cliente. o mismo se aplica a la tecnología/software, donde el código fuente actúa como la última fuente de verdad, almacenada en un repositorio rastreable y estructurado. Este formato y la arquitectura del sistema se pueden aplicar a funciones e infraestructuras de investigación. Proponemos que los equipos de investigación tomen una página de los libros de jugadas de ingeniería o CRM y creen para sí mismos una única fuente de verdad.
Este artículo también se encuentra disponible en audio (Por el momento, solo en inglés)
- Resumen
- Repositorio de Insights
- ¿Qué es un repositorio?
- ¿Cuáles son los elementos de data clave que un repositorio debería tener?
- 1. Insights / Temas / Historias
- 2. Observaciones e información dividida en «nuggets»
- 3. Datos crudos y evidencia de tu investigación
- 5 Características de un repositorio de insights
- Principales Beneficios de tener un Repositorio de Insights
- Workflows eficientes y reutilizables
- Acceso rápido y autónomo a la información
- Enhanced knowledge access and graph
- Added transparency and no loss of information
- Quick turnaround studies
- Democratized data & unified warehousing
- Real-time analytics
- Business Need & ROI of Insights / Research Repositories
- Research and the data is extremely siloed
- The same research is conducted multiple times
- Research reports go unnoticed
- Workflows are arbitrary
- Knowledge discovery is non-existent
- Proving the ROI of research
- The Business Taxonomy
- Nodes, Metadata, Tagging & Attributes – A fresh approach to Organizing
- Workflows
- Operational & Execution Challenges
- Leadership buy-in and alignment
- Researcher Education
- External Research Vendors
- Fragmentation of Repositories
- Maturity
- Method to create and manage an insights repository with steps
- 1. Appoint the team to manage the insights repository
- 2. Organize your existing and past research
- 3. Add supporting insights & evidence
- 4. Synthesize and analyze data
- 5. Create critical insights, findings, and reports
- 6. Tag and share insights
- Authors
Insights Repository
¿Qué es un repositorio?
“Un repositorio es cualquier plataforma, sistema, unidad, base de datos, herramienta de colaboración de contenido, biblioteca, base de conocimientos, wiki o archivador que almacena datos de investigación, notas, transcripciones, imágenes, videos, grabaciones, hallazgos, conocimientos, informes, metadatos, etc. para apoyar el consumo y la reutilización por parte de todo el equipo.”
— Research Repositories Workshops, 2020, Un proyecto de Research Ops Community
Queremos ampliar aún más esta definición al señalar que la diferencia clave entre un repositorio y los archivos de almacenamiento es triple:
- El contenido está indexado y se puede buscar, acceder y navegar fácilmente
- Hay un elemento cronológico en los datos.
- El equipo lo acepta como definitivo y como la fuente autorizada
En otras palabras, un repositorio de insights se define como una fuente central de información a la que los investigadores y las partes interesadas pueden acceder a la investigación que ha realizado una organización, tanto en el pasado como en el presente. Tener una plataforma consolidada para organizar, explorar, buscar y descubrir todos los datos de investigación de una empresa en una ubicación organizada.
¿Cuáles son los elementos clave de los datos que debe tener un repositorio de insights?
Un Repositorio de Insights consta de tres niveles fundamentales de datos:
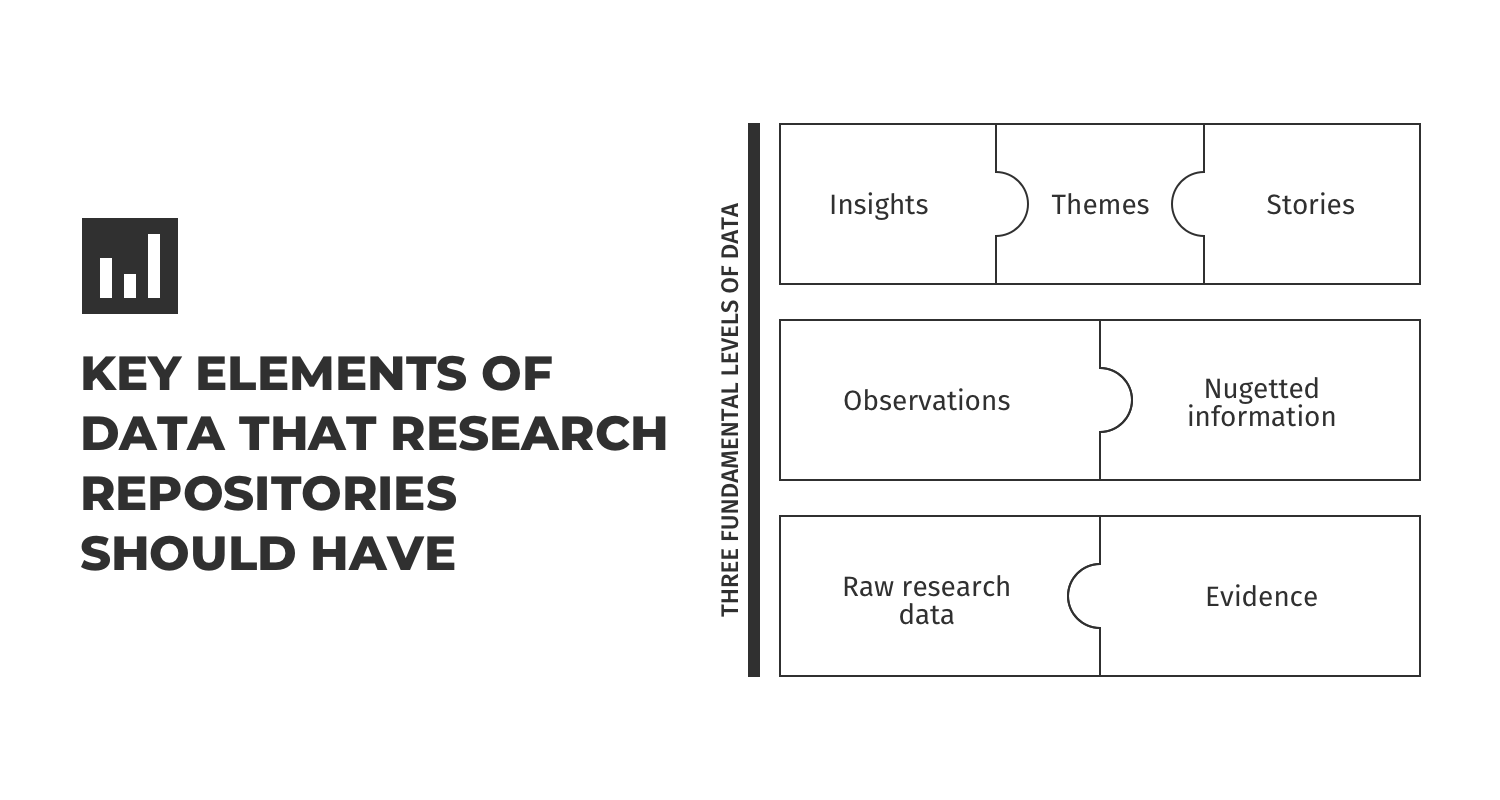
1. Insights/Temas/Historias
En un nivel holístico, el repositorio de insights consta de información etiquetada, indexada y unificada. Esto proviene de estudios pasados y existentes de diferentes tipos de investigación, incluidos estudios cualitativos y cuantitativos, investigación de usuarios, estudios personalizados, estudios de modelado de investigación avanzada y más. Todas estas ideas se pueden buscar fácilmente con el uso de taxonomía empresarial y metaetiquetas. Estos conocimientos también monitorean los gastos de costos, el ROI de los estudios y otros factores que brindan información sobre el tiempo y los recursos gastados.
2. Observaciones e información dividida en «nuggets»
El nivel secundario de un repositorio de insights tiene como objetivo proporcionar información a un nivel aún más granular de estudios que realiza un determinado equipo o producto, conocimientos de estudios de seguimiento longitudinal, mejoras de productos, mensajes de marketing o una campaña que emana de una iniciativa determinada. Este nivel también almacena presentaciones y resultados para que el conocimiento tribal de los estudios en silos esté disponible para que todos lo vean.
3. Datos y pruebas de investigación en bruto
El componente final de este repositorio son los datos reales, que incluyen llamadas de clientes, datos de investigación de proveedores, cuestionarios, estudios etiquetados de taxonomía comercial, datos cualitativos y cuantitativos, IDI, datos de comportamiento del cliente y más. Todo esto son datos sin filtrar que se pueden consultar y aprovechar cuando sea necesario.
5 Características de un Repositorio de Insights
Después de hablar con varios investigadores, partes interesadas comerciales y empresas que han implementado alguna versión de un repositorio de conocimientos, hemos identificado los cinco aspectos más importantes.
Estas características clave conducirían a una adopción y uso generalizados y actuarían como piedra angular y guía para repositorios de investigación exitosos.

1. Recuperable
Una característica esencial de un repositorio de insights es que debe ser muy fácil acceder a los investigadores y otras partes interesadas del negocio por igual. Los miembros del equipo deben obtener rápidamente información más fácil de entender y consumir sin escribir múltiples consultas en diversas plataformas. Reunir toda esta información en una sola plataforma es fundamental. Los investigadores deberían poder obtener información de estudios anteriores para respaldar sus estudios en curso o evitar que realicen un estudio nuevamente. Las partes interesadas del negocio también deberían poder obtener información basada en lo que es importante para ellos, incluida la información demográfica, los costos del proyecto, los estudios longitudinales y más.
2. Accesible
Todas las partes interesadas relevantes en un negocio deberían querer aprovechar el repositorio de insights para su recopilación de información. La herramienta debe ser fácilmente accesible para los miembros en todos los niveles para que la adopción de la herramienta sea más fácil. También debería ser fácil dibujar análisis mientras se evitan flujos de trabajo complicados y torpes. A las partes interesadas les gusta tener acceso a datos que sean poderosos pero fáciles de representar para no tener que mirar informes y gráficos complejos.
3. Trazable
Un repositorio de insights exitoso no debe ser solo hermosos gráficos y números sin vincular nunca a los datos. Ser capaz de casar las ideas con los datos es crucial. Es imprescindible crear una forma de volver a conectarse a los datos de origen si es necesario. Tiene que haber una referencia a los datos originales o sin procesar que genere confianza, ya que se basa en la evidencia. El repositorio de insights debe vincularse a todos los datos, incluso desde hace años, si es necesario validarlos o incluso verificar si las inferencias realizadas en ese momento se mantienen hoy. Los datos fáciles de rastrear también garantizan que los datos multivariados aún tengan sentido en el caso de estudios repetidos o seguimiento longitudinal. Por último, con datos rastreables, los investigadores deberían sacar nuevas conclusiones y conocimientos con la misma rapidez.
Creemos que hay dos elementos clave aquí:
- Timestamp
- Fuente de datos y evidencia
Cada elemento debe tener una marca de tiempo: las perspectivas y los datos cambian rápidamente y los artículos tienen una vida útil. Lo mismo se aplica a la conexión de conocimientos con datos sin procesar o evidencia. Esto nos permite generar confianza en los insights con trazabilidad y responsabilidad hasta la fuente o los datos sin procesar.
4. Accesible
Para que un repositorio de insights tenga altas tasas de adopción y marque la diferencia, debe ser accesible para todas las partes interesadas relevantes. Incluso los recién llegados a los equipos de investigación deberían tener acceso desde el primer día para entrar y tomar decisiones informadas e inferencias sobre estudios anteriores sin perder tiempo. Para un éxito tremendo, la adopción de la herramienta debe ser inmediata y constante. Su repositorio de insights debe ser la única fuente de verdad, y los miembros del equipo no deberían tener que mirar varias carpetas, informes, documentos y hojas de cálculo para descubrir insights.
5. Seguridad
Como su repositorio de insights albergará datos de múltiples fuentes y es una única fuente de verdad para su organización, es probable que contenga información que puede ser confidencial y delicada. Para que su repositorio de insights tenga un uso generalizado en organizaciones globales, la herramienta debe cumplir con las pautas de los mandatos del gobierno federal y otros gobiernos locales de almacenamiento de datos y seguridad, como cumplir con GDPR y más. También debe haber políticas vigentes para la retención, el cifrado, el anonimato y la eliminación de datos.
Beneficios principales de tener un repositorio de insights
Un repositorio de insights consta de múltiples partes móviles que hacen que la vida de los investigadores y las organizaciones sea mejor y más eficiente. Algunos de sus importantes beneficios y ventajas incluyen:
- Democratizar el acceso a los conocimientos. En cualquier momento, en cualquier lugar, bajo demanda.
- Reducir la dependencia de los humanos y el conocimiento tribal
- Permitir que los investigadores reutilicen y se basen en el conocimiento y la investigación existentes.
Flujos de trabajo eficientes y reutilizables
El uso de un repositorio de insights ayuda a armar nuevos procesos de admisión de proyectos, gestión de proyectos, actualizaciones de estado, plantillas, etc., que tradicionalmente han sido engorrosos e ineficientes para los profesionales de la información. Con la configuración de flujos de trabajo de cómo fluyen los datos desde la fase de solicitud hasta la información que se etiqueta y supervisa en el repositorio de información del usuario, una estructura claramente definida ahorra mucho tiempo y recursos.
Acceso rápido y autoservicio de insights
Después de completar los estudios de investigación, existe un repositorio significativo y en el que se pueden realizar búsquedas de datos, hallazgos clave y materiales de todos los proyectos. Ahora se vuelve ventajoso y sencillo para los investigadores, los equipos de información y las partes interesadas buscar datos actuales o pasados en una plataforma unificada que brinda acceso rápido a los insights.
Gráfico y acceso a conocimientos mejorados
Aprovechar investigaciones anteriores que ya se han realizado en lugar de comenzar desde cero mejora el acceso al conocimiento y el gráfico. Es fácil obtener conocimiento sobre estudios anteriores y construir líneas de tendencia de descubrimientos pasados con las brechas existentes actuales. Dado que el conocimiento colectivo se agrupa, existe un descubrimiento continuo interno constante sobre pepitas de sabiduría, resúmenes de costos para mostrar el ROI y más, fácilmente.
Mayor transparencia y sin pérdida de información
Una ventaja adicional de este centro de conocimiento es que hay mayor transparencia en el diseño y el proceso de la investigación, desde que alguien solicita la investigación hasta los equipos que la realizan y publican los informes. También es fácil ubicar estudios que se realizaron anteriormente y los miembros del equipo involucrados, por lo que luego es fácil extraer información en función de varios criterios.
Estudios de respuesta rápida
El acceso a información como tipos de estudios, cuestionarios, herramientas utilizadas, encuestados y más ayudas para realizar estudios de respuesta rápida donde los investigadores y otras partes interesadas relevantes ya conocen muchos aspectos administrativos. Esto permite aprovechar la inteligencia pasada e implementar estudios más rápidos que brindan información procesable más rápido.
Datos democratizados y almacenamiento unificado
Los datos de todos los equipos y unidades comerciales fluyen hacia un almacén central unificado con conocimiento tribal mitigado y taxonomía comercial uniforme, lo que convierte al centro de investigación en una ventanilla única para todo tipo de información. Hay una mayor retención en la gestión y accesibilidad de los datos, lo que garantiza que no tenga que buscar en varios lugares y comunicarse con varias partes interesadas para dar sentido a los datos. En este caso, también se simplifica la gestión de datos de investigación multivariados.
Análisis en tiempo real
Al usar un repositorio de datos e insights, hay acceso instantáneo y en tiempo real a datos y análisis. No solo eso, con la ayuda de etiquetas inteligentes e inteligencia artificial (IA), es posible obtener información sobre proyectos que son relevantes e interesantes. Esta característica hace que el uso del repositorio de información sea aún más lucrativo para los investigadores y las partes interesadas del negocio para aprovechar los análisis en tiempo real en la investigación de mercado amplificada y reutilizable.
Necesidad comercial y ROI de Insights/Repositorios de investigación
Ahora existe una estructura para comprender por qué existe una necesidad comercial de un repositorio de insights, pero las causas reales que requirieron acelerar dicha solución. En términos generales, la investigación se divide en dos grupos: investigación generativa que tiene como objetivo desbloquear oportunidades para las marcas e investigación evaluativa que prueba ciertos casos de uso y soluciones.
Hay un abandono fundamental de la gestión del conocimiento y los insights escalables en el corazón de estos dos casos. Tradicionalmente, ha habido problemas para profundizar en datos anteriores, poner al día a los nuevos miembros, aprovechar investigaciones anteriores, perder conocimientos en estudios individuales, conocimientos tribales y más. Para que el proceso de información sea escalable, las empresas y organizaciones deben superar estos problemas específicos.
Los problemas más destacados que requirieron la necesidad de un repositorio de insights son:
La investigación y los datos están extremadamente aislados
Las organizaciones realizan investigaciones en varias frecuencias, escalas y complejidades. Diferentes grupos dentro de una organización pueden realizar investigaciones ellos mismos o enviarlas a investigadores especializados que luego realizan estudios. La mayoría de las empresas tienen una combinación de subcontratación e investigación interna, y esto conduce a diferentes sistemas de registro y clasificación de la investigación.
Añádase a esto los factores variables de investigación entre otras divisiones, unidades de negocio y ubicaciones geográficas con diferentes tipos de estudios. Piense en estudios de clientes, investigación de usabilidad, grupos de enfoque en línea, investigación cuantitativa y luego los montones de datos de encuestas recopilados. Todos estos encuentran su camino en pequeños grupos pero nunca se democratizan. Los datos de la investigación están muy aislados y no hay forma de que alguien pueda dar sentido a estos datos después de un período específico. Incluso si estos datos se encuentran por casualidad, hay mucho conocimiento tribal en los datos que es difícil de entender.
La misma investigación es realizada múltiples veces
Otro factor importante que provocó la necesidad del nacimiento de los repositorios de investigación es la cantidad de veces que se realiza la misma investigación. La mayoría de las veces, cuando los nuevos miembros se unen a los equipos, salen y ejecutan estudios que ya se han completado antes y extraen información que se ha recopilado antes. Esto contribuye a la pérdida de tiempo y dinero y reduce el retorno de la inversión (ROI) de los conocimientos, al aumentar los esfuerzos de duplicación. La mayoría de las veces, las partes interesadas de las empresas desconfían de las ideas que les envían los investigadores. Con el tiempo, dado que la investigación y los datos hacen eco de sentimientos similares, les quita credibilidad a los investigadores y a los informes de investigación.
Los informes de investigación pasan desapercibidos
Los informes de investigación se producen al final de cada estudio, pero desafortunadamente, hay poca o ninguna estructura sobre cómo se producen, almacenan o distribuyen. Agregue a esto la complejidad de cómo los investigadores interpretan los datos, y la falta de alineación de los conocimientos con los problemas comerciales conduce a que estos informes queden enterrados. La mayoría de las veces, estos informes también son difíciles de encontrar, ya que viven en varios lugares y, con el tiempo, se vuelven obsoletos. Otro problema con los informes es que no existe una estructura basada en datos para los hallazgos o recomendaciones, lo que genera un mayor nivel de desconfianza entre las partes interesadas.
Los flujos de trabajo son arbitrarios
Las organizaciones grandes y complejas no tienen conocimiento de la investigación realizada a mayor escala y las partes interesadas involucradas simplemente debido a la complejidad de los datos recopilados. Además, varias partes interesadas ven los problemas comerciales de manera diferente y pueden solicitar varios puntos de vista para estudios similares. Los formularios de admisión de proyectos varían de persona a persona, y los métodos de investigación también son variados. Por lo tanto, cada flujo de trabajo se vuelve excepcionalmente arbitrario y, por lo tanto, dar sentido a los procesos después de un tiempo determinado se vuelve muy complejo.
El descubrimiento del conocimiento es inexistente.
Cada uno de los proyectos de investigación tiene un por qué. La investigación y las encuestas de investigación se realizan para necesidades específicas: marca, rotación de clientes, etc., donde estas taxonomías comerciales generalmente se capturan en conversaciones, correo electrónico y conocimiento tribal. Tradicionalmente, no había forma de configurar taxonomías comerciales y configurar metaetiquetas para investigar estudios de los cuales extraer información. Incluso los nuevos miembros no tienen transparencia en los estudios anteriores y los hallazgos y aprendizajes de estudios anteriores en un repositorio centralizado.
El mercado y las herramientas existentes están fragmentados
Uno de los mayores desafíos que justificó un repositorio de conocimientos es que el mercado y las herramientas existentes están muy fragmentados. Agregue a la complejidad de varias soluciones, software, pilas tecnológicas actuales y herramientas de comunicación y administración. Es una mezcla de múltiples niveles de conversaciones e interacciones en varios niveles. Hay algunas herramientas para solicitar estudios, herramientas de gestión de proyectos, software para gestionar estudios, informes de investigación y más. No solo esto, hay herramientas de comunicación interna, y luego la comunicación con los proveedores, sus API, etc., se suma a la complejidad del flujo y la gestión del conocimiento.
Demostrar el ROI de la investigación
Debido a la naturaleza fragmentada de estas herramientas, los ciclos de investigación se vuelven más largos y complicados. Otros factores conducen a la complejidad de la investigación y pueden sesgar con los cuestionarios utilizados, los proveedores utilizados, la muestra de encuestados a la que se llegó, las herramientas involucradas y más. Debido a esto, la mayoría de los estudios de investigación críticos toman mucho tiempo desde la concepción hasta la fase de información procesable mientras siguen aplicando una capa de complejidad e incertidumbre. Por lo tanto, cuando se toman decisiones, es un desafío vincular el proceso de investigación con el factor final real y hace que sea difícil justificar el ROI de la investigación.
Estos factores contribuyeron a la necesidad de armar un sistema que haga que el proceso de investigación y conocimiento sea más simple, eficiente y rápido.
The Business Taxonomy
Nodos, metadatos, etiquetado y atributos: un nuevo enfoque para organizar
Creemos que es fundamental tener una forma flexible y preparada para el futuro de organizar proyectos y conocimientos, de modo que, a medida que el negocio crece y cambia, la flexibilidad para reorientar la taxonomía es dinámica. Esto significa usar «Etiquetas» en lugar de categorías rígidas y crear un gráfico de conocimiento flexible de ideas.
Las etiquetas y los atributos asociados con insights deben ser dinámicos y flexibles, en los que se pueden introducir nuevas etiquetas/conceptos en cualquier momento y las etiquetas más antiguas caducan sin afectar sustancialmente el modelo de datos.
También creemos que las etiquetas/conceptos deben estar anidados y jerárquicos. Esto permite un modelo de categorización de árbol y nodo más natural, que representa con precisión el mundo real.
Flujos de trabajo
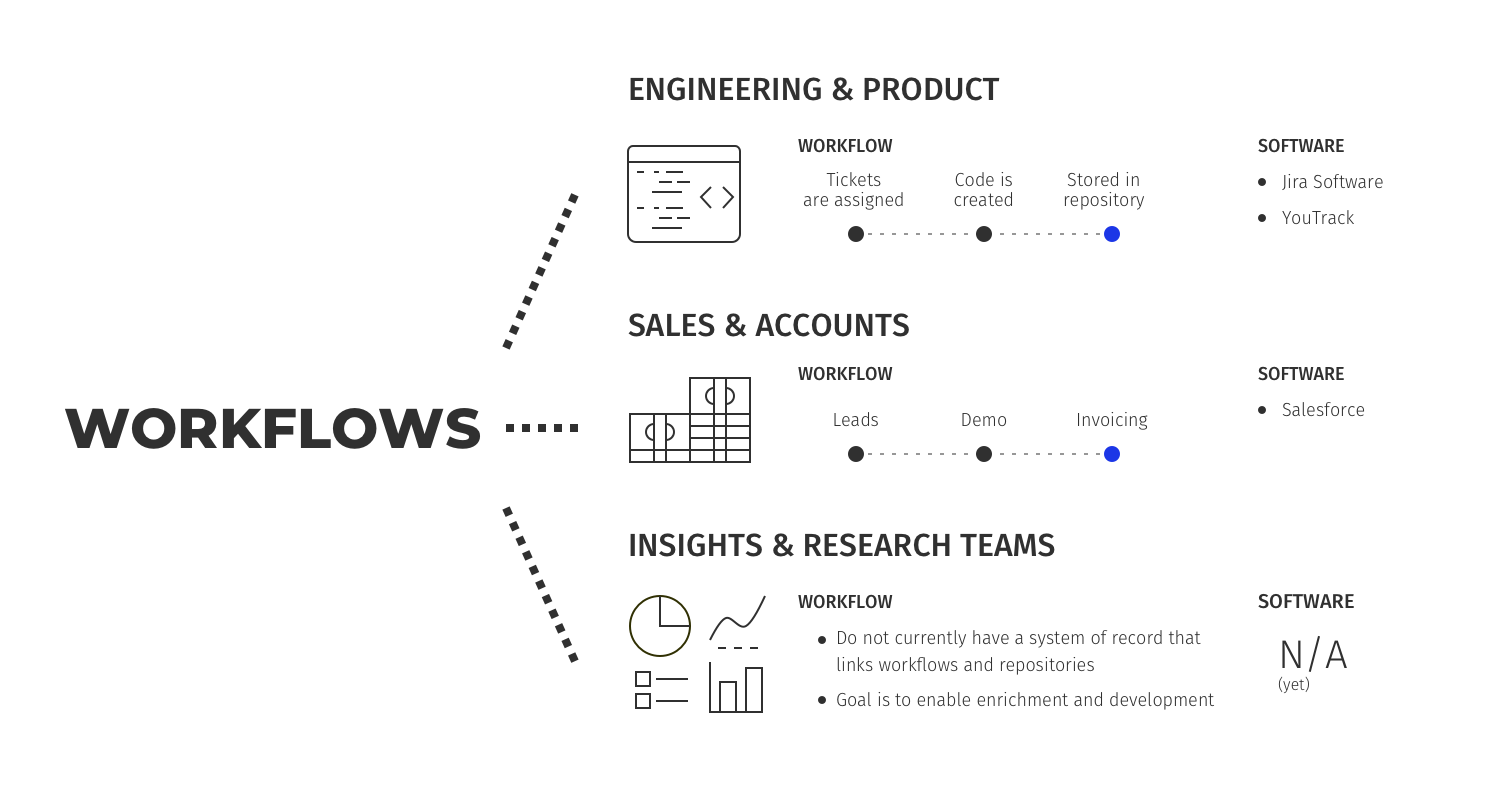
Echemos un vistazo a cómo funcionan los equipos de ingeniería y productos en un entorno acelerado. Todos utilizan algún tipo de sistema de emisión de tickets/sistema de seguimiento de errores/problemas para gestionar sus flujos de trabajo. Allí se gestionan la asignación, la propiedad y el estado. Jira, YouTrack et al. El código se escribe y almacena en repositorios de código fuente y las actualizaciones y compilaciones consiguientes se vinculan a los tickets. Existe un ciclo virtuoso de integración entre los flujos de trabajo y los repositorios y la salida (compilaciones).
Veamos también los equipos de ventas y cuentas: utilizan plataformas de CRM para almacenar datos de clientes, así como un conjunto de herramientas conectadas que definen los flujos de trabajo. Ventas->Demostración->Facturación. Con App Marketplace, Salesforce ha construido una posición dominante al permitir varios flujos de trabajo además de los datos de CRM/Repositorio.
Diseñar un modelo de repositorio sin integrarlo en los flujos de trabajo existentes o permitir que los flujos de trabajo existentes se agreguen al repositorio sería contraproducente. Al igual que los pequeños equipos de ventas e ingeniería, que inicialmente comienzan con una hoja de cálculo y finalmente migran a un sistema de registro, como Salesforce o Jira, los equipos de análisis e investigación deben tener un sistema de registro para definir sus flujos de trabajo y tener una interconexión profunda entre los flujos de trabajo y los repositorios. En otras palabras, las herramientas de flujo de trabajo permiten el enriquecimiento y desarrollo del repositorio.
Desafíos operativos y de ejecución
A medida que los equipos implementaron repositorios de investigación en varias empresas, realizamos entrevistas 1 a 1 con aproximadamente 10 empresas e identificamos algunos desafíos que la mayoría de ellos enfrentaron.
Compromiso y alineación del liderazgo
Como con la mayoría de las iniciativas, el liderazgo debe ver el beneficio económico y el ROI para instituir dicho proceso/sistema. Sin su aceptación subyacente, tales iniciativas intelectualmente están destinadas al fracaso. Gran parte de nuestra investigación mostró que los líderes están dispuestos a experimentar con tales ideas y probar gradualmente el ROI en su propio contexto. Esto permite un modelo más fácil para convencer a los líderes de pilotar un sistema de este tipo con un equipo o una subsección de un equipo y determinar la eficacia y luego tomar una decisión.
Educación del investigador
Tenemos que educar/empoderar y exigir a los investigadores que sigan algunas pautas básicas sobre etiquetado, nomenclatura y organización. Al igual que los vendedores tienen que ser engatusados para poner datos en el CRM de manera organizada, donde hay capacitación en ventas, anticipamos que los investigadores deben ser guiados a través de este proceso: recopilar los datos y organizarlos e informar sobre ellos de manera estructurada. Esperar mágicamente una herramienta o una plataforma para resolver el cambio de comportamiento humano, sin capacitación y diligencia, será contraproducente.
Proveedores de investigación externos
Los proveedores externos publican un desafío interesante en lo que respecta a la taxonomía y el seguimiento de las pautas. También plantea desafíos en términos de acceso y contribución fácil al repositorio. ¿Permitimos que los proveedores accedan al repositorio del sistema o hacemos que los datos pasen a través de un proceso de datos/gobernanza?
Fragmentación de Repositorios
Al igual que en un entorno complejo, la fragmentación de datos y procesos, incluidos los repositorios, seguramente ocurrirá. Los silos se crean con proveedores, equipos e incluso dentro de los equipos, las limitaciones tecnológicas crean silos. Es posible que los equipos de investigación no quieran dejar de lado su control sobre los datos y la narrativa.
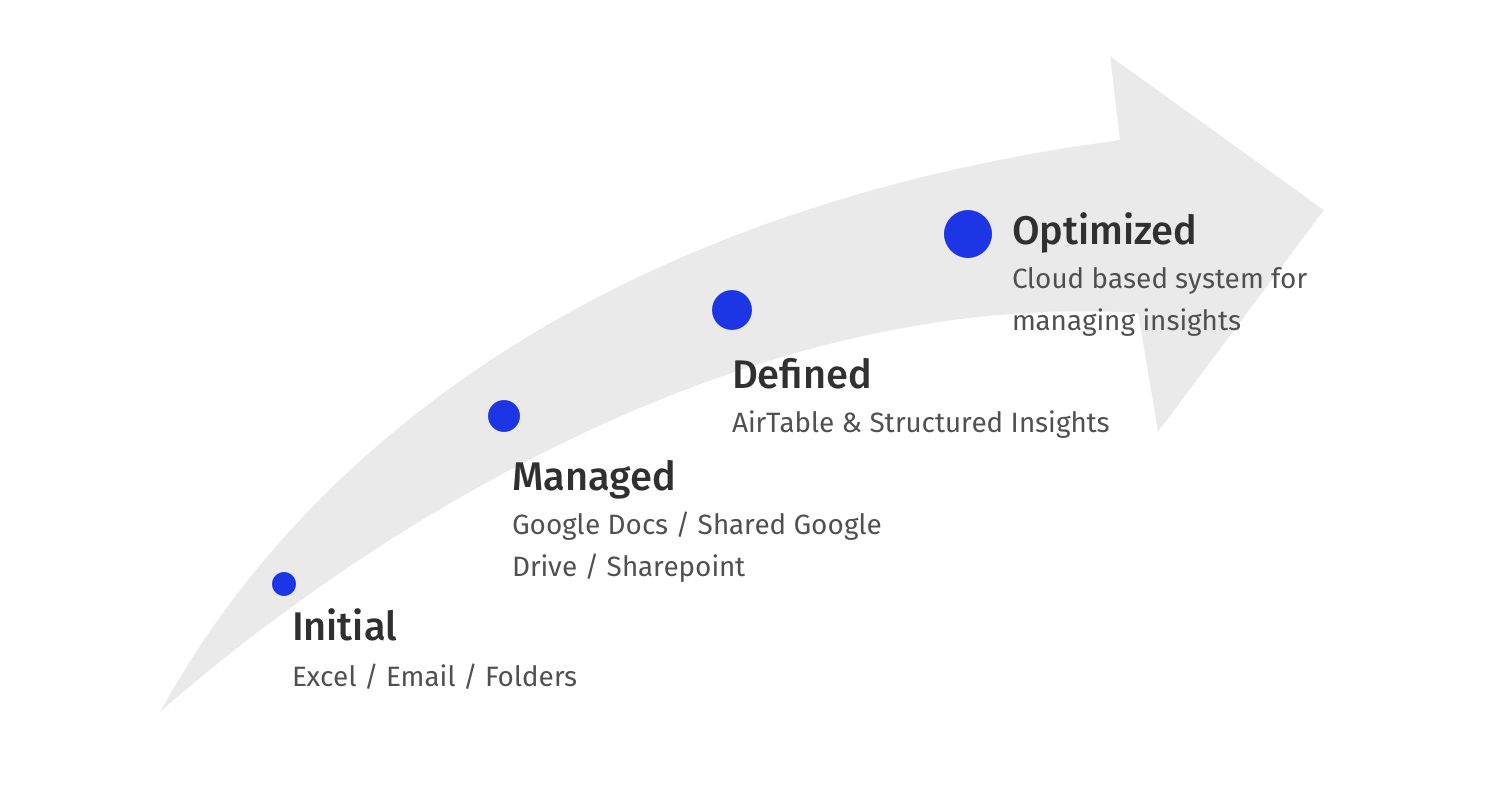
Madurez
Muchas empresas comienzan con herramientas y carpetas simples para administrar la información. Estos pueden variar desde una carpeta organizada en el escritorio del investigador hasta una unidad de Google compartida o una carpeta de Sharepoint donde todos los investigadores contribuyen con archivos y datos.
Escala de madurez y niveles
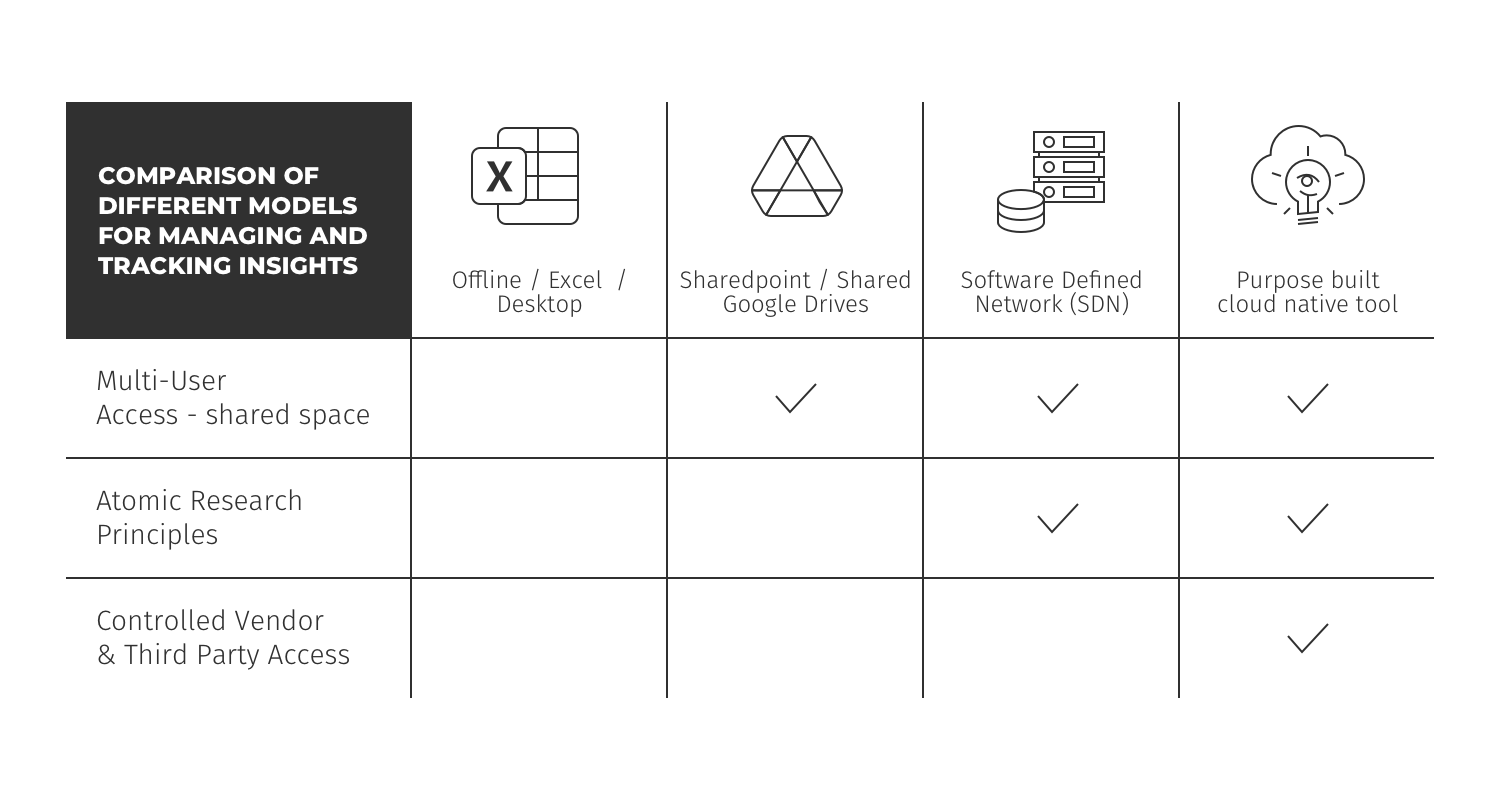
La siguiente tabla describe las ventajas y desventajas de los diferentes modelos para administrar y rastrear información;
Método para crear y administrar un repositorio de insights con pasos
Si se gestiona adecuadamente, la adopción de un repositorio de insights a nivel organizativo es muy alta. Este repositorio de información del usuario también puede resolver problemas de investigación a nivel macro y micro y ser un facilitador fundamental para descubrir y administrar información procesable. Pero para poder hacer todas estas cosas, debe haber una claridad extrema de todas las partes interesadas sobre los procesos actuales y las cosas que necesitan para llegar a una plataforma unificada de investigación y conocimientos que sea escalable y proporcione valor. Sería útil si también pensara en su pila de tecnología existente utilizada para investigación y colaboración, proveedores y API de proveedores, centros de gestión de conocimiento existentes, flujos de trabajo y otros factores internos antes de decidirse por la plataforma.
Este es el método para crear y administrar un repositorio de insights en seis sencillos pasos:
1. Designe el equipo para administrar el repositorio de insights
Los investigadores y el equipo de investigación de base amplia de su organización deben mantener y poseer el repositorio de insights. Incluso dentro del grupo, designe líderes y campeones de investigación que impulsen la adopción de la herramienta internamente y en toda la organización. Dicho equipo y sus miembros deben tener una visión general de la investigación realizada en toda la organización y con varias partes interesadas internas y externas. Este equipo también debe ser responsable de administrar la taxonomía, configurar flujos de trabajo y ayudar a obtener insights del centro de conocimientos. Asignar a este equipo la tarea de aumentar la adopción en toda la organización ayuda a que esta plataforma sea la única fuente de verdad e información en toda la organización. Si bien varios miembros pueden contribuir y contribuir a la adopción y el éxito de esta plataforma, debe haber líderes empresariales que puedan desbloquear completamente su potencial.
Una métrica simple para medir el éxito sería la cantidad de usuarios, partes interesadas que consumen información del repositorio mensualmente. Cualquier sistema debería poder rastrear esto e informar al respecto, para la rendición de cuentas interna.
2. Organice su investigación existente y pasada
Una vez que haya decidido el equipo y la herramienta, es vital definir la taxonomía comercial, una agrupación de etiquetas y más para organizar la investigación existente y pasada. Esto podría ser por proyectos, productos, ubicaciones o cualquier otro criterio de su elección. La organización adecuada ayuda a consolidar la investigación y los conocimientos de diversas fuentes y crea de inmediato un gráfico de conocimiento sólido y escalable. No solo eso, las partes interesadas del negocio y los investigadores de toda la organización obtienen información sobre el volumen, la escala, los métodos, las herramientas y el ROI de la investigación.
Un beneficio adicional de construir su taxonomía por adelantado es construir detalles incluso dentro de los equipos de investigación y conocimientos sobre un sentido compartido de lo que es importante y cómo tenemos una visión común del negocio.
3. Agregue información y evidencia de apoyo
Al agregar notas, datos, observaciones y comentarios, puede hacer que el repositorio de conocimientos sea extraordinariamente sólido y poderoso. Reunir información relevante y luego etiquetarla de la manera que funcione mejor para su marca le permite obtener los conocimientos más concretos y precisos que necesitan los equipos en general. Puede parecer que se agrega demasiada información, pero si se etiqueta correctamente con todas las perspectivas y datos relevantes, se crea la versión más potente de su repositorio de insights. Con la adición de prácticas recomendadas, notas y otra información de apoyo, su centro de investigación seguirá creciendo y se reducirá el tiempo para obtener información procesable.
También sugerimos que tener la capacidad de «profundizar» en la evidencia es fundamental. Incluso las capturas de pantalla de la evidencia son mucho mejores que no tener ningún vínculo entre los conocimientos y la evidencia. Piense en esto como la sección de «referencias» en un diario. Esas notas al pie y referencias nos mantienen a todos honestos y permiten el escrutinio público del producto terminado.
4. Sintetizar y analizar datos
Al usar una herramienta que le permite administrar sus datos de investigación, tanto cualitativos como cuantitativos y su análisis en una plataforma, obtiene lo mejor de ambos mundos: administración de productos, plataforma de investigación y herramientas de comunicación en una ubicación centralizada. Esto también permite la capacidad de reunir todos los datos relevantes en una ubicación centralizada para administrarlos mejor e incluso acceder más tarde si es necesario.
Considere el uso de API para vincular conocimientos e informes con hallazgos y evidencia sin procesar. Casi todos los proveedores tienen API abiertas para que los sistemas interactúen entre sí.
5. Cree perspectivas, hallazgos e informes críticos
Es imperativo crear informes fácilmente digeribles y fragmentos de información en su centro de investigación. La reducción de estudios complejos en informes con etiquetas inteligentes que consisten en información y hallazgos críticos ofrecería la mejor adopción para el repositorio. No solo esto, estos hallazgos brindan una vista instantánea de cada informe y luego brindan la capacidad de comparar informes, sacar conclusiones, identificar resúmenes de costos y justificar el ROI de la investigación. Al crear una vista instantánea de cada estudio de investigación por nombre, solicitante, unidad comercial, metodología de investigación, cronogramas, costos y más, ofrece la información más concreta sobre la plataforma y, por lo tanto, aumenta la adopción.
6. Etiquete y comparta ideas
Por último, etiquetar los estudios de investigación con la taxonomía comercial adecuada y las metaetiquetas ayudan a agrupar, indexar y crear informes de información que permiten realizar búsquedas. Agrupar o agregar varias etiquetas no es un problema siempre que puedan ayudar a sacar inferencias inmediatas. Etiquetar y compartir información proporciona a las partes interesadas una idea del proceso de investigación. Esto también ayuda a aumentar la adopción y el uso. Las agrupaciones pueden tener información superpuesta, pero eso está bien para que todas las partes interesadas relevantes según el trabajo, el estudio de investigación, el grupo empresarial y más tengan acceso a la información.

