Das Verständnis des Unterschieds zwischen synthetischen Daten und Scheindaten ist für jeden wichtig, der mit Tests, Forschung oder KI-Entwicklung arbeitet. Beide werden verwendet, wenn echte Daten nicht verfügbar sind oder aufgrund von Datenschutzbestimmungen nicht weitergegeben werden können. Sie helfen Teams beim Aufbau, Testen und Verbessern von Systemen, ohne dass tatsächliche Benutzerdaten verwendet werden.
Synthetische Daten werden von Computern so erstellt, dass sie wie echte Daten aussehen und sich auch so verhalten, während Scheindaten erstellt werden, um zu testen, ob die Dinge richtig funktionieren. Sie könnten synthetische Daten verwenden, um ein KI-Modell zu trainieren und Scheindaten, um zu prüfen, ob Ihr Formular oder Dashboard wie erwartet funktioniert.
In diesem Blog erklären wir Ihnen, was synthetische Daten und Scheindaten bedeuten, wie sie sich unterscheiden und wie Sie entscheiden können, welche Methode am besten zu Ihrem Projekt passt.
Wie funktionieren synthetische Daten in einer Umfrage?
Synthetische Daten sind Daten, die von Computern erstellt werden, anstatt von echten Menschen erhoben zu werden. Sie werden so erstellt, dass sie wie echte Umfrageantworten aussehen und sich auch so verhalten, aber sie stammen nicht von echten Teilnehmern. Das bedeutet, dass Sie sie sicher verwenden können, ohne sich Gedanken über den Datenschutz oder persönliche Details machen zu müssen.
In einer Umfrage können Sie mit synthetischen Daten testen, wie alles funktioniert, bevor Sie echte Antworten erfassen. Sie können zum Beispiel Ihre Umfrage mit computergenerierten Antworten füllen, um zu prüfen, ob die Fragen in der richtigen Reihenfolge gestellt werden, ob die Verzweigungslogik richtig funktioniert und ob die Ergebnisse in den Berichten klar dargestellt werden. Das ist wie ein Probelauf, der Ihnen hilft, Fehler frühzeitig zu erkennen und zu beheben.
Beispiel:
Stellen Sie sich vor, Sie erstellen eine Umfrage zum Kundenfeedback. Bevor Sie sie verschicken, generieren Sie gefälschte Antworten, um zu testen, ob Ihre Umfrage und Ihre Berichte korrekt funktionieren. Sobald alles reibungslos funktioniert, können Sie die Umfrage für echte Teilnehmer starten.
Synthetische Daten in Umfragen helfen Ihnen, Ihre Umfrage zu testen, zu verbessern und vorzubereiten, bevor sie echte Menschen erreicht. Das spart Zeit, schützt die Daten und stellt sicher, dass Ihre Umfrage genau so funktioniert, wie Sie es erwarten.
Lesen Sie auch: Synthetischer Datensatz: Was es ist, Vorteile + Verwendung
Wie funktionieren Mock-Daten in einer Umfrage?
Scheindaten sind erfundene Informationen, die zum Testen einer Umfrage verwendet werden, bevor echte Antworten erfasst werden. Sie helfen Forschern und Entwicklern sicherzustellen, dass alles wie erwartet funktioniert, von der Darstellung der Fragen bis zur Anzeige der Ergebnisse. Scheindaten müssen nicht perfekt oder realistisch sein. Sie müssen Ihnen nur dabei helfen, zu überprüfen, ob Ihre Umfrage reibungslos funktioniert.
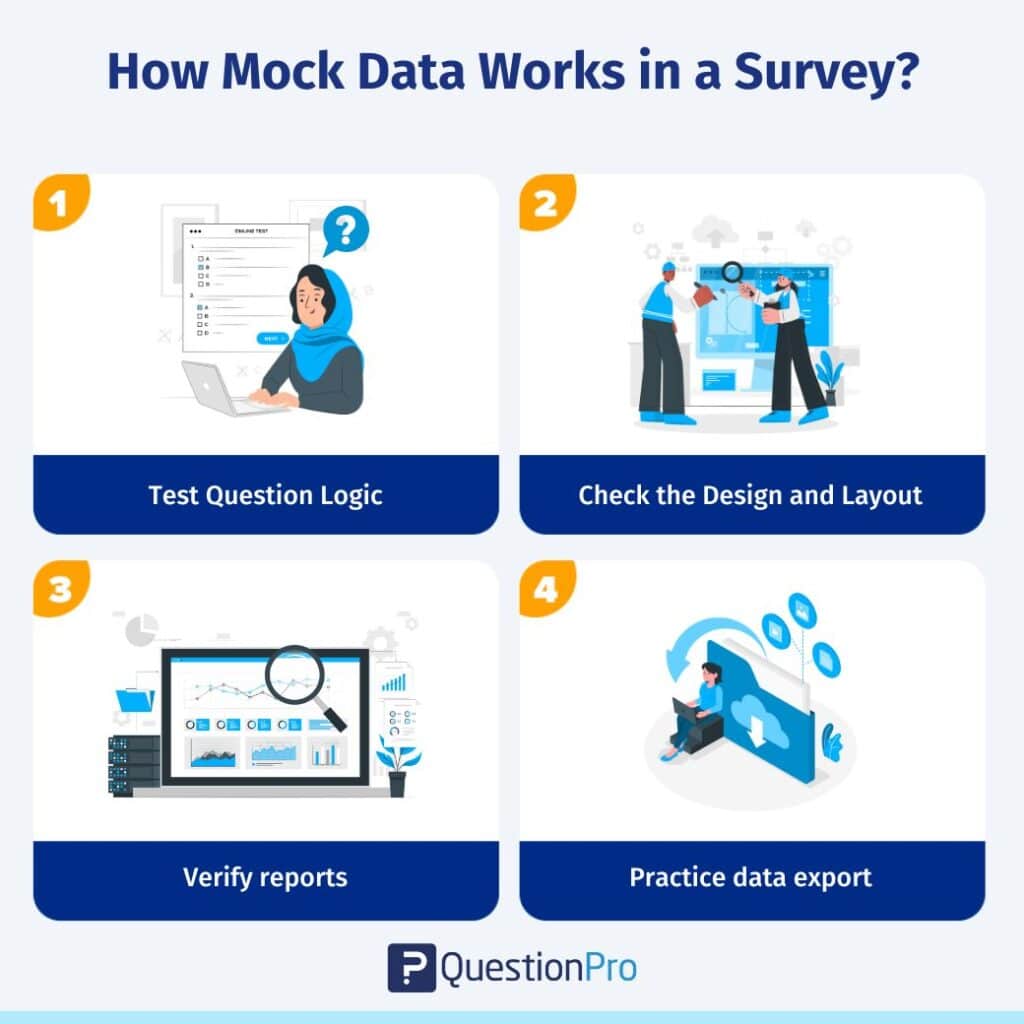
Wenn Sie eine Umfrage erstellen, können Sie Scheindaten verwenden:
- Testen Sie die Fragenlogik: Vergewissern Sie sich, dass Fragen mit Sprunglogik oder Verzweigungen zu den richtigen Abschnitten gehören.
- Prüfen Sie Design und Layout: Prüfen Sie, ob die Umfrage sowohl auf dem Desktop als auch auf mobilen Geräten sauber aussieht.
- Überprüfen Sie Berichte: Bestätigen Sie, dass Diagramme, Grafiken und Zusammenfassungen nach der Erfassung der Antworten korrekt angezeigt werden.
- Üben Sie den Datenexport: Testen Sie, wie die Ergebnisse aussehen, wenn Sie sie in Tools wie Excel oder Analyse-Dashboards herunterladen.
Beispiel:
Angenommen, Sie entwerfen eine kurze Umfrage zur Mitarbeiterzufriedenheit. Bevor Sie sie an Ihr Team weitergeben, füllen Sie sie mit 50 Scheinantworten aus, um zu prüfen, ob alle Fragen die richtigen Antworten erfassen und ob das Dashboard die richtigen Durchschnittswerte anzeigt. Wenn alles gut funktioniert, können Sie die Scheindaten löschen und mit dem Sammeln von echtem Feedback beginnen.
Was sind die Hauptunterschiede zwischen synthetischen Daten und Mock-Daten?
Synthetische Daten und Scheindaten mögen ähnlich klingen, aber sie dienen ganz unterschiedlichen Zwecken. Beide werden verwendet, wenn echte Daten nicht verfügbar sind oder nicht weitergegeben werden können, doch die Art und Weise, wie sie erstellt und angewendet werden, macht sie einzigartig. Das Verständnis dieser Unterschiede hilft Teams bei der Auswahl des richtigen Typs für Testumfragen, Forschung oder Produktentwicklung.
| Aspekt | Synthetische Daten | Mock-Daten |
| Definition | Künstlich erstellte Daten, die mithilfe von Algorithmen oder KI-Modellen Informationen aus der realen Welt imitieren. | Beispielhafte oder gefälschte Daten, die manuell oder mit einfachen Tools erstellt wurden, um Systeme und Designs zu testen. |
| Zweck | Wird für realistische Analysen, KI-Training und Simulationen verwendet, wenn reale Daten nicht oder nur eingeschränkt verfügbar sind. | Wird zum Testen von Anwendungen, Layouts oder Formularen verwendet, bevor echte Daten verfügbar sind. |
| Erstellungsmethode | Erzeugt durch maschinelles Lernen, Simulationen oder statistische Modelle. | Manuell oder mit zufälligen Datengeneratoren und Mock-APIs erstellt. |
| Realismus | Sehr realistisch und nach realen Mustern und Zusammenhängen. | Einfach und zufällig; spiegelt nicht die tatsächlichen Datenbeziehungen wider. |
| Datenschutz | Schützt die Privatsphäre, da es keine echten persönlichen Daten verwendet. | Schützt die Privatsphäre durch die Verwendung gefälschter Werte, eignet sich aber nicht für detaillierte Analysen. |
| Datenqualität | Hochwertig und logisch konsistent; kann reale Verteilungen imitieren. | Geringere Qualität; konzentriert sich eher auf Funktionalität als auf Realismus. |
| Anwendungsfälle | KI-Modelltraining, prädiktive Analysen, Forschung und datenschutzkonforme Weitergabe von Daten. | Softwaretests, UI-Design, Demos und Validierung von Prototypen. |
| Komplexität | Erfordert fortschrittliche Tools und Algorithmen zur Erstellung. | Einfach zu erstellen mit manueller Eingabe oder Generatoren. |
| Wert für die Analyse | Hochwertig, weil es für realistische Modellierung und Entscheidungsfindung verwendet werden kann. | Geringer Wert für die Analyse; nur nützlich für das Testen von Prozessen. |
| Beispiel | Ein synthetischer Datensatz, der Krankenhausdaten für die medizinische Forschung simuliert. | Gefälschte Namen und E-Mail-Adressen wurden verwendet, um ein Anmeldeformular zu testen. |
Empfohlene Lektüre: Synthetische Daten vs. simulierte Daten: Was ist der Unterschied?
Die Wahl zwischen synthetischen und Scheindaten
Die Wahl zwischen synthetischen Daten und Scheindaten hängt davon ab, was Sie erreichen wollen. Beide Arten von Daten sind nützlich, aber sie dienen unterschiedlichen Zielen. Sowohl synthetische Daten als auch Scheindaten spielen eine wichtige, sich ergänzende Rolle bei der Gestaltung von Umfragen und im Forschungsprozess. Die Befragten aus allen Branchen gaben an, dass sie jede Art von Daten in verschiedenen Phasen verwenden, um Tests, Datenschutz und Leistung zu verbessern.
Mock-Daten: Ideal für den Entwurf von Umfragen und Pre-Launch-Tests
Die Mehrheit der Befragten gab an, dass sie in der Anfangsphase der Umfrageentwicklung Scheindaten verwendet haben. Dies hilft den Teams, die Struktur und den Ablauf einer Umfrage zu validieren, ohne dass echte Antworten benötigt werden.
Den Teilnehmern zufolge werden Scheindaten häufig für folgende Zwecke verwendet:
- Testen von Verzweigungslogik, Piping und Verzweigungen
- Vorschau von Fragenlayouts und Formatierung
- Sicherstellen, dass Eingabefelder, Überprüfungsregeln und Berechnungen wie erwartet funktionieren
- Schnelle Erstellung von Prototypen zur Überprüfung durch die Stakeholder
Mock-Daten bieteen Schnelligkeit und Komfort, so dass Forscher schnell iterieren können, bevor sie die eigentliche Umfrage einsetzen.
Synthetische Daten: Unverzichtbar für die Analyse nach der Erhebung und den Schutz der Privatsphäre
Sobald die echten Beantwortungen erfasst sind, geben viele Befragte an, dass sie auf synthetische Daten zurückgreifen, um tiefere Analysen zu ermöglichen und den Datenschutz zu gewährleisten. Synthetische Daten werden besonders geschätzt, wenn die Ergebnisse extern geteilt oder KI-Modelle auf Umfragedaten angewendet werden.
Zu den wichtigsten Verwendungszwecken gehören:
- Erstellen von datenschutzfreundlichen Versionen echter Antwortdaten zur Analyse oder Weitergabe
- KI-Tools auf Umfrageergebnissen trainieren, ohne sensible Informationen preiszugeben
- Simulation des Verhaltens der Befragten oder Durchführung von Was-wäre-wenn-Szenarien auf der Grundlage synthetischer Umfrageergebnisse
- Sicherstellung der Einhaltung von Datenschutzbestimmungen (z.B. GDPR, HIPAA)
Die Teilnehmer der Umfrage betonten, dass Scheindaten und synthetische Daten nicht austauschbar sind, sondern sich ergänzen. Mock-Daten unterstützen eine schnelle und flexible Entwicklung, während synthetische Daten eine sichere, skalierbare und aufschlussreiche Analyse ermöglichen, nachdem echte Daten gesammelt wurden.
Durch die Kombination von beidem können Teams bessere Umfragen erstellen, effizienter testen und mit Zuversicht analysieren, ohne den Datenschutz oder die Qualität zu beeinträchtigen.
Fazit
Synthetische Daten und Scheindaten spielen beide eine wertvolle Rolle bei modernen Tests, Forschung und Entwicklung. Synthetische Daten bieten realistische, datenschutzfreundliche Informationen, die zum Trainieren von KI-Modellen, zum Simulieren des Verhaltens in der realen Welt oder zum Analysieren komplexer Systeme verwendet werden können, ohne dass persönliche Details preisgegeben werden.
Mock-Daten hingegen sind einfacher und schneller zu generieren. Sie eignen sich daher ideal für das Testen von Prototypen, die Validierung von Designs oder die Überprüfung von Funktionen, bevor echte Daten verfügbar sind. Die beiden können sogar zusammenarbeiten. Mock-Daten helfen bei frühen Tests, während synthetische Daten später eine fortgeschrittenere und zuverlässigere Datenanalyse unterstützen.
Mit QuestionPro können Teams beide Ansätze problemlos erforschen. Die Plattform ermöglicht es Benutzern, strukturierte Mock-Datensätze zum Testen von Umfragen oder Dashboards zu erstellen und echte Daten zu sammeln, die in synthetische Versionen für tiefergehende Untersuchungen und Modellierungen umgewandelt werden können. Diese Flexibilität hilft Forschern, Entwicklern und Unternehmen, sicher zu experimentieren, effizient zu testen und bessere Entscheidungen auf der Grundlage genauer und konformer Daten zu treffen.
Häufig gestellte Fragen (FAQs)
Antwort: Synthetische Daten werden von Algorithmen oder KI-Modellen erzeugt, um reale Datenmuster für die Analyse oder das KI-Training zu imitieren. Mock-Daten werden manuell oder mit einfachen Tools erstellt, um Systeme, Formulare oder Prototypen zu testen.
Antwort: Verwenden Sie synthetische Daten, wenn Ihr Projekt realistische Informationen benötigt, die sich wie echte Daten verhalten. Sie sind ideal für das Training von KI-Modellen, Datensimulationen und datenschutzsichere Tests. Verwenden Sie Mock-Daten, wenn Sie nur Layouts, Benutzerabläufe oder Systemfunktionen testen und keine echten Muster oder Beziehungen benötigen.
Antwort: Synthetische Daten können echte Daten nicht vollständig ersetzen, aber sie sind eine gute Alternative, wenn echte Daten durch Datenschutzgesetze eingeschränkt sind. Sie können helfen, KI-Modelle zu trainieren, Algorithmen zu testen und Analysen durchzuführen, ohne sensible Informationen preiszugeben.
Antwort: Die Generierung synthetischer Daten ist völlig künstlich und enthält keine persönlichen oder identifizierbaren Informationen. Das macht sie nützlich für die Einhaltung von Datenschutzbestimmungen wie GDPR oder HIPAA, da Unternehmen Daten analysieren oder weitergeben können, ohne zu riskieren, dass echte Benutzerdaten preisgegeben werden.
Antwort: Ja. Viele Teams verwenden Mock-Daten für frühe Tests und synthetische Daten später für fortgeschrittenere Validierungen. Mock-Daten helfen bei Design und Funktionalität, während synthetische Daten in späteren Test- oder Analysestufen für mehr Tiefe, Realismus und Schutz der Privatsphäre sorgen.