




Die Welt ist in Bewegung, und künstliche Daten sind einer der Schlüsselfaktoren, die die Zukunft neu gestalten. Mit der Einführung von KI und maschinellem Lernen in der Industrie werden Datenerweiterungen und synthetische Datensätze für effiziente, ethische und skalierbare Trainingsmodelle immer wichtiger.
Im Gegensatz zu realen Daten können künstliche Daten angepasst werden, um Verzerrungen zu reduzieren, die Privatsphäre zu schützen und ungewöhnliche Situationen nachzubilden. Branchen wie das Gesundheitswesen, das Finanzwesen und die selbstfahrende Technologie entwickeln sich schneller und verantwortungsvoller.
Angesichts der grenzenlosen Möglichkeiten ist es klar, dass die nächste Ära des technologischen Fortschritts von den Daten angetrieben wird, die wir entwerfen, nicht nur von den Daten, die wir sammeln. Wir werden die Datenerweiterung erforschen, um Sie über das Datenzeitalter zu informieren.
Was ist Datenerweiterung?
Data Augmentation ist eine Technik des maschinellen Lernens und der Datenanalyse, die einen Datensatz künstlich vergrößert, indem sie modifizierte Versionen bestehender Daten erstellt. Anstatt neue Daten zu sammeln, werden Transformationen wie:
- Bilder: Drehen, spiegeln, verwischen und Farben ändern.
- Text: Synonyme austauschen, paraphrasieren, übersetzen.
- Audio: Passen Sie die Geschwindigkeit und die Tonhöhe an und fügen Sie Hintergrundgeräusche hinzu.
Ein Bild kann zum Beispiel gespiegelt, gedreht oder aufgehellt werden, um mehrere Versionen desselben Bildes zu erstellen. In ähnlicher Weise können Textdaten mit Synonymen ausgetauscht oder Sätze umgeschrieben werden, um den Datensatz zu diversifizieren. Dadurch erhöht sich die Menge der Trainingsdaten und die Variabilität, so dass die KI-Modelle mehr lernen können.
Erfahren Sie mehr: Modelle, Arten und Anwendungen des maschinellen Lernens
Warum Datenerweiterungstechniken?
Wenn Sie nicht genügend Trainingsdaten haben, können Sie das Problem durch Datenerweiterung lösen. Anstatt tonnenweise neue Daten zu sammeln (was langsam und teuer sein kann), nehmen wir das, was wir bereits haben, um mehr„gefälschte, aber realistische“ synthetische Muster zu erstellen.
Auf diese Weise werden die Modelle besser, ohne dass Sie endlose Beispiele aus der realen Welt benötigen.
Wichtigste Vorteile:
- Spart Zeit und Geld: Sie müssen nicht tonnenweise neue Daten sammeln.
- Verhindert Überanpassung: Hilft den Modellen, mit neuen, unbekannten Daten gut zu funktionieren.
- Bringt Abwechslung: Dadurch kann die KI besser mit Rauschen, Winkeln und Veränderungen in der realen Welt umgehen.
- Gleicht Datensätze aus: Behebt Klassenungleichgewichte (z. B. seltene Krankheiten in der medizinischen KI).
Es ist so, als ob Sie Ihrer KI mehr„Übungsszenarien“ geben, damit sie sich nicht verschluckt, wenn die Dinge unvorhersehbar werden. Erweiterungen, ob in Form von Fotos, Text oder Audio, machen Modelle innovativer und zuverlässiger.
Einschränkungen von Augmented Data
Die Datenerweiterung ist zwar leistungsstark, aber kein Allheilmittel. Hier sind ihre wichtigsten Einschränkungen:
- Risiko der Überanpassung: Wenn die erweiterten Daten dem Original zu ähnlich sind, könnten sich die Modelle Muster einprägen, anstatt allgemeine Regeln zu lernen. Wenn Sie zum Beispiel jedes Bild auf die gleiche Weise umdrehen, lernt die KI nichts Neues.
- Unrealistische Ergebnisse: Schlecht konzipierte Augmentierungen (z. B. extremes Rauschen in Bildern oder unsinnige Textvertauschungen) können„falsche“ Daten erzeugen, die Modelle in die Irre führen. Zum Beispiel könnte ein verschwommener Tumor-Scan eine medizinische KI verwirren.
- Lücken im Bereich: Augmentierte Daten erfassen möglicherweise nicht die Komplexität der realen Welt. Ein selbstfahrendes Auto, das nur mit Simulationen für sonnige Tage trainiert wurde, könnte zum Beispiel bei starkem Regen versagen.
- Datenschutz-Illusionen: Synthetische Daten sind nicht immer wirklich anonym. Es besteht die Gefahr einer Re-Identifizierung, wenn die Muster zu sehr an reale Personen angelehnt sind (z. B. bei synthetischen Gesundheitsdaten).
- Bias-Verstärkung: Wenn die Originaldaten verzerrt sind, kann die Augmentation diese Fehler verstärken. Gesichtserkennungssysteme, die auf begrenzte Hauttonvariationen trainiert wurden, schneiden zum Beispiel bei unterrepräsentierten Gruppen schlechter ab.
Erweiterte Daten sind ein Hilfsmittel und kein Ersatz für ein durchdachtes Design und vielfältige, reale Daten. Nutzen Sie es mit Bedacht!
Methoden zur Datenerweiterung für die Forschung
Datenerweiterung ist nicht nur für KI, sondern auch ein leistungsstarkes Werkzeug zur Verbesserung von Forschungsdatensätzen. Im Folgenden finden Sie Methoden, die in der quantitativen und qualitativen Forschung eingesetzt werden, um diesen Prozess zu vereinfachen.
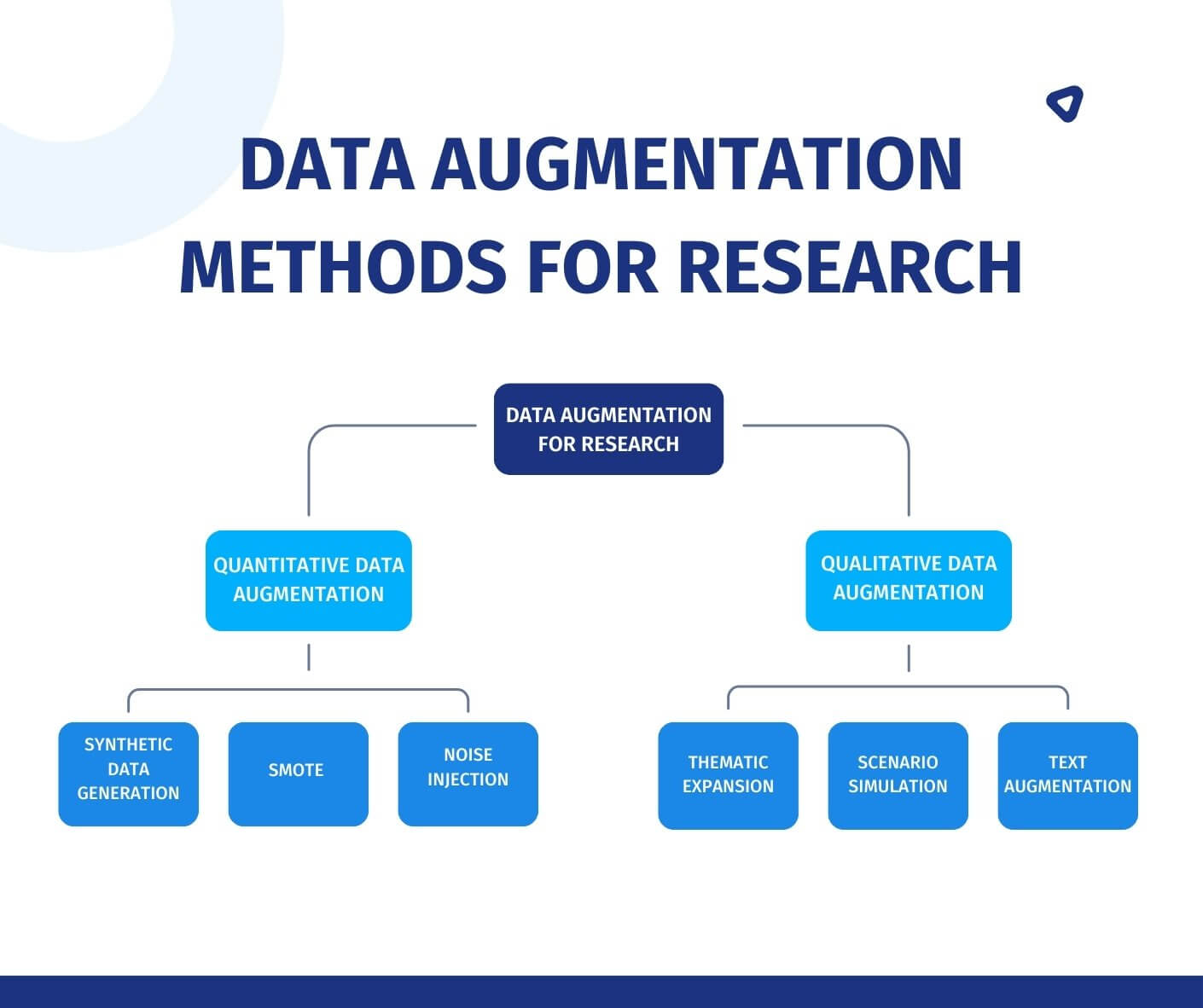
1. Quantitative Datenerweiterung
Für numerische oder strukturierte Daten:
- Synthetische Daten erzeugen: Verwenden Sie statistische Modelle für die Generierung synthetischer Daten wie Regression oder Bootstrapping, um synthetische Antworten zu erstellen, die reale Umfragetrends widerspiegeln.
- SMOTE (Synthetic Minority Oversampling Technique): Ausgleichen Sie unausgewogene Datensätze (z.B. seltene Kundenfeedback-Kategorien), indem Sie synthetische Minderheitenklassen-Stichproben erstellen.
- Rauschinjektion: Um die Robustheit des Modells zu testen, fügen Sie den numerischen Daten (z.B. den Umfragewerten) leichte Zufallsschwankungen hinzu.
2. Qualitative Datenerweiterung
Für Text, offene Antworten oder thematische Daten:
- Thematische Erweiterung: Verwenden Sie NLP-Tools, um offene Antworten zu paraphrasieren oder zu erweitern (z.B. Interviewtranskripte).
- Szenario-Simulation: Erstellen Sie hypothetische Szenarien (z.B. „Was wäre wenn“-Fragen), um das Feedback der Teilnehmer zu erweitern.
- Text-Erweiterung: Tauschen Sie Synonyme aus oder formulieren Sie Sätze in qualitativen Antworten um, um Sprachmuster zu variieren.
Durch die Verbindung von quantitativer Strenge mit qualitativer Tiefe können Forscher die Datenknappheit überwinden und reichhaltigere, besser verwertbare Erkenntnisse gewinnen.
Datenerweiterung in der quantitativen Forschung
Es stärkt die quantitative Forschung, indem es die Vollständigkeit, Ausgewogenheit und Repräsentativität von Datensätzen durch Imputation, Erzeugung synthetischer Daten und Bootstrapping verbessert.
- Umfragebasierte Studien
In der umfragebasierten Forschung ist die Datenerweiterung von entscheidender Bedeutung, da sie Lücken wie fehlende Antworten oder kleine Stichprobengrößen schließt. Techniken wie die Imputation ergänzen fehlende Daten mit Hilfe statistischer Methoden (z.B. Regressionsmodelle oder k-nächste Nachbarn), so dass die Datensätze für die Analyse vollständig sind.
Replikationsmethoden wie das Bootstrapping oder die synthetische Generierung von Befragten erweitern kleine Erhebungsstichproben, um die statistische Zuverlässigkeit zu erhöhen. Bei Studien im Bereich der öffentlichen Gesundheit verringert die Replikation demografischer Untergruppen die Non-Response-Verzerrung, was zu genaueren Schätzungen der Prävalenz von Krankheiten führt.
- Kleine oder unausgewogene Datensätze
Kleine oder verzerrte Datensätze sind ein großes Problem in der quantitativen Forschung. Techniken zur Datenerweiterung, wie SMOTE (Synthetic Minority Oversampling Technique) oder GANs (Generative Adversarial Networks), erzeugen synthetische Stichproben, um unterrepräsentierte Klassen auszugleichen.
In der medizinischen Forschung gibt es bei seltenen Krankheiten vielleicht nur eine Handvoll Fälle, und die Ergänzung von MRT-Scans oder Laborergebnissen mit synthetischen Anomalien hilft den Modellen, Muster zu erkennen, ohne sich zu sehr anzupassen. Systeme zur Erkennung von Finanzbetrug verwenden erweiterte Transaktionsdaten, um seltenes betrügerisches Verhalten zu simulieren.
- Bias Reduction and Generalization Improvements
Augmentation diversifies the training data to reduce bias. For example:- Gesichtserkennungsmodelle verwenden verschiedene Beleuchtungs-/ethnische Merkmale, um die Genauigkeit bei verschiedenen Hauttönen zu verbessern.
- Synthetische sozioökonomische Daten verringern Stichprobenverzerrungen in politischen Studien.
- Eine Kreuzvalidierung zeigt, dass die erweiterten Modelle bei realen Aufgaben 10-20% besser abschneiden.
Datenerweiterung in der qualitativen Forschung
Es verbessert die qualitative Forschung, indem es synthetische Texte, Audiodateien oder Bilder erzeugt, um die Analyse zu vertiefen, Datenknappheit zu beheben und verborgene Muster aufzudecken. Sie erfordert jedoch eine sorgfältige ethische Überwachung, um die Authentizität zu wahren.
- Natürliche Spracherweiterung für Interviews und Transkripte
Qualitative Forscher verwenden natürliche Spracherweiterung, um Textdaten aus Interviews, Fokusgruppen oder offenen Umfragen zu ergänzen. Techniken wie Paraphrasierung, Ersetzung von Synonymen oder Rückübersetzung (z.B. vom Englischen ins Französische und zurück) erzeugen sprachliche Variationen, ohne die Bedeutung zu verändern.
- Ethische Erwägungen und Interpretierbarkeit
Das Erweitern qualitativer Daten wirft ethische Fragen auf: Verändern synthetische Erzählungen die ursprüngliche Absicht der Teilnehmer?
In der Forschung zur psychischen Gesundheit können selbst geringfügige Änderungen an Interviewtranskripten die gelebten Erfahrungen falsch darstellen. Forscher müssen die Interpretierbarkeit sicherstellen, indem sie die Augmentationsmethoden transparent dokumentieren und die Ergebnisse anhand der Rohdaten validieren.
- Use in Content Analysis and Thematic Coding
Augmentation adds to textual datasets for deeper analysis:- Synthetische Erzählungen in HIV-Stigma-Studien zeigen kulturelle Unterschiede im Ausdruck.
- Tools wie NVivo kodieren automatisch erweiterte Texte, um die thematische Analyse zu beschleunigen.
- Seien Sie vorsichtig: Eine übermäßige Augmentation kann künstliche Themen schaffen und die auf Originaldaten basierenden Ergebnisse untergraben.
Dies schafft ein Gleichgewicht zwischen kurzen Aufzählungspunkten für Techniken, Beispielen und Listen und Absätzen für Kontext und Erklärungen. Lassen Sie es mich wissen, wenn Sie weitere Optimierungen benötigen!
Datenerweiterung in verschiedenen Branchen
Ist Datenerweiterung nur etwas für Techniklabors? Nein, sie revolutioniert die Art und Weise, wie Forscher an quantitative und qualitative Studien herangehen. Hier erfahren Sie, wie sie bei verschiedenen Forschungsmethoden eingesetzt wird:
- Gesundheitswesen: Erweitern Sie medizinische Datensätze (z. B. durch die Erstellung synthetischer Röntgenbilder oder MRTs), um die KI-gestützte Erkennung von Krankheiten zu verbessern. Erstellen Sie synthetische Patientendaten zum Trainieren von Vorhersagemodellen, ohne die Privatsphäre zu gefährden.
- Autonome Fahrzeuge: Simuliert verschiedene Fahrbedingungen (Regen, Nebel), um Wahrnehmungsalgorithmen mit begrenzten Daten aus der realen Welt zu trainieren.
- Fertigung: Erweitert Sensordaten, um Geräteausfälle vorherzusagen oder künstliche Defekte zu erzeugen und so die KI für die Qualitätskontrolle zu verbessern.
- Sozialwissenschaften: Erzeugt synthetische Interviewantworten oder paraphrasierte Transkripte, um breitere thematische Muster zu erkennen. Erweitert ethnografische Daten (z.B. virtuelle Szenarien), um menschliches Verhalten in unterrepräsentierten Kontexten zu untersuchen.
- Marktforschung: Erweitert kleine Fokusgruppendatensätze mit KI-generiertem Verbraucherfeedback, um verborgene Vorlieben aufzudecken. Simuliert verschiedene Benutzerinteraktionen (z.B. Chatbot-Dialoge), um qualitative Modelle zu testen.
- Inhaltsanalyse: Verwendet NLP, um Textkorpora, wie z.B. Nachrichtenartikel und Umfragen mit offenem Ende, für eine tiefergehende Stimmungs- oder Diskursanalyse zu erweitern.
Von der Verbesserung der statistischen Verlässlichkeit in quantitativen Studien bis hin zur Aufdeckung nuancierter Erkenntnisse in qualitativen Arbeiten – die Datenerweiterung hilft Forschern, Datenknappheit, Verzerrungen und ethische Einschränkungen zu überwinden, ohne dabei auf Strenge zu verzichten.
Erfahren Sie mehr: Der Einfluss von synthetischen Daten auf die moderne Forschung.
Erweiterte Daten vs. Synthetische Daten
Hier finden Sie eine übersichtliche Vergleichstabelle zwischen Augmented Data und synthetischen Daten im Forschungskontext:
| Merkmal | Erweiterte Daten | Synthetische Daten |
| Definition | Modifizierte oder erweiterte Versionen von echten Daten. | Künstlich generierte Daten, die reale Muster imitieren. |
| Zweck | Erweitern Sie bestehende Datensätze, ohne die ursprüngliche Bedeutung zu verlieren. | Ersetzen oder ergänzen Sie knappe/private Echtdaten. |
| Quantitative Verwendung | Bootstrapping von Umfrage-Stichproben. | Generieren Sie synthetische Daten aus klinischen Studien. |
| Qualitative Verwendung | Paraphrasierte Interviewtranskripte. | KI-generierte, offene Umfrageantworten. |
| Profis | Bewahrt die Integrität der Kerndaten. | Behebt Datenknappheit. |
| Nachteile | Risiko der Überanpassung bei übermäßiger Verwendung. | Es kann an Realismus fehlen. |
Profi-Tipps:
- Nutzen Sie erweiterte Daten, um bestehende Datensätze zu stärken.
- Verwenden Sie einen synthetischen Datensatz, um fehlende oder sensible Daten zu ersetzen.
Wie eine Kombination aus QuestionPro Research Suite und Datenerweiterung für Forscher funktioniert!
Die Research Suite von QuestionPro und die Techniken zur Datenerweiterung helfen Forschern, größere Datensätze zu erstellen und genauere KI/ML-Modelle zu trainieren, insbesondere in den Bereichen Computer Vision und Deep Learning. Hier sehen Sie, wie sie zusammenarbeiten:
1. Anreicherung von Trainingsdatensätzen
QuestionPro ist der Ausgangspunkt für die Erfassung hochwertiger Eingabedaten, einschließlich Textantworten, Bildern oder Verhaltensdaten.
Forscher können bei der Arbeit mit Textdaten aus Umfragen Techniken wie Paraphrasierung oder die Ersetzung von Synonymen verwenden, um mehr Variationen zu erzeugen, ohne die ursprüngliche Bedeutung zu verändern.
2. Verbesserung der Modellleistung
Die Kombination von QuestionPro’s Techniken zur Datensammlung und -erweiterung ermöglicht es Forschern, robustere Trainingsdatensätze für tiefe neuronale Netzwerke zu erstellen.
Fortgeschrittene Techniken zur Datenerweiterung, einschließlich generativer adversarischer Netzwerke (GANs), können synthetische Daten mit denselben statistischen Eigenschaften wie reale Daten erzeugen und gleichzeitig deren Vertraulichkeit wahren. Dies ist besonders nützlich für das Training von Objekterkennungsmodellen und anderen Deep Learning-Anwendungen, bei denen vielfältige Daten für die Modellgeneralisierung entscheidend sind.
3. Anwendungen in der Forschung
Die Kombination von QuestionPro Research Suite und Datenerweiterung in der Marktforschung ermöglicht es Forschern, Preismodelle zu testen, indem sie echte Umfragedaten mit synthetischen demografischen Variationen kombinieren.
Sozialwissenschaftler können diese Techniken nutzen, um synthetische Interviewtranskripte zu erstellen, um thematische Kodierungsrahmen zu testen und zu verfeinern.
QuestionPro ist die Grundlage für hochwertige Eingabedaten; die Datenerweiterung erweitert und bereichert diese Daten für weitere Analysen. Zusammen sind sie die Komplettlösung für Forscher, die mit traditionellen statistischen Modellen und KI-Systemen arbeiten.
Fazit
Die Kombination von QuestionPro (für eine robuste Datenerfassung) mit Augmentierungsmethoden (zur Erweiterung des Datensatzes) ist ein entscheidender Vorteil für das Gesundheitswesen und die Sozialwissenschaften.
Forscher können genauere KI-Modelle trainieren, verborgene Muster finden und seltene Szenarien simulieren, ohne die Datenintegrität oder den Datenschutz zu gefährden.
Angesichts des technologischen Fortschritts liegt die Zukunft der Forschung in der intelligenten Gestaltung von Daten, nicht nur in deren Sammlung. Der strategische Einsatz von erweiterten und synthetischen Daten ermöglicht es Forschern, weiter zu gehen, mehr zu verallgemeinern und fächerübergreifend zu innovieren.
Häufig gestellte Fragen(FAQs)
Antwort: Data Augmentation ist eine Technik des maschinellen Lernens und der Datenanalyse, bei der ein Datensatz künstlich vergrößert wird, indem modifizierte Versionen der vorhandenen Daten erstellt werden.
Antwort: Die Datenerweiterung verbessert die quantitative Forschung, indem sie die Qualität und Zuverlässigkeit der Datensätze verbessert. Sie behebt fehlende Daten durch Imputationstechniken, erweitert kleine Stichproben durch Bootstrapping oder die Generierung synthetischer Befragter und gleicht verzerrte Datensätze mit Methoden wie SMOTE oder GANs aus.
Antwort: Die Technik birgt das Risiko einer Überanpassung, wenn es den erweiterten Daten an Vielfalt mangelt. Sie kann zu unrealistischen Ergebnissen führen, die die Modelle in die Irre führen und die Komplexität der realen Welt nicht erfassen, wie z.B. Wetterschwankungen für autonome Fahrzeuge. Darüber hinaus können synthetische Daten Risiken für die Privatsphäre bergen, wenn sie reale Personen zu sehr widerspiegeln, und sie können bestehende Verzerrungen im Originaldatensatz verstärken.
Antwort: Nein, erweiterte Daten und synthetische Daten sind nicht dasselbe. Augmentierte Daten basieren auf realen Datensätzen und werden modifiziert, um erweiterte, aber abgeleitete Versionen zu erstellen. Synthetische Daten werden vollständig künstlich erzeugt, um reale Muster zu imitieren. Sie werden oft verwendet, wenn die Originaldaten begrenzt oder sensibel sind.



