




¿Qué sabes de los valores perdidos de una encuesta? Durante el proceso de recolección de datos mediante la técnica de la encuesta, es muy habitual que una parte de los cuestionarios que emitimos a nuestro objetivo de estudio o target no sean completados parcial o totalmente, por lo que puede dificultar el análisis final y sesgar los resultados de nuestra investigación. Entre las causas más comunes que provocan este acontecimiento podemos encontrar:
– Preguntas ambiguas en el cuestionario
– Desinterés por contestar la encuesta
– Preguntas comprometedoras
Aunque estas causas afectan principalmente al resultado final y a la representatividad de la muestra seleccionada, existen una serie de estrategias de depuración y de imputación que pueden reducir el sesgo y optimizar el resultado final de nuestra investigación de mercado.
Técnicas para tratar valores perdidos
Técnicas de Depuración
El proceso de Depuración de Datos consiste en la evaluación de la calidad de la información recogida, aumentando la calidad de ésta, con tal de evitar análisis poco rigurosos. Las estrategias de depuración más usadas son:
– Listado de valores: Se trata de buscar en la matriz de datos los valores que están fuera del rango de respuesta. Estos valores se pueden considerar como perdidos, o se puede estimar el valor correcto a partir de otras variables (Imputación).
Ejemplo: En la variable Sexo, cuyos valores son 1 = Hombre y 2 = Mujer, encontramos un 3 en la matriz de datos.
– Preguntas filtro: Se trata de comparar el número de respuestas de una categoría filtro y otra categoría filtrada. Si se observa alguna anomalía que no pueda tener solución, se considerará como valor perdido.
Ejemplo: La pregunta filtro A tiene 11 respuestas que conduce a la pregunta filtrada B, mientras que la que conducen a la pregunta filtrada C tiene 9 respuestas. Sin embargo, observamos que en la pregunta B se han dado 14 respuestas (2 más de las que estaban previstas), por lo tanto, no existe coincidencia entre la categoría filtro y la categoría filtrada.
– Consistencias Lógicas: Se comprueban las respuestas que puedan ser consideradas contradictorias entre sí.
Ejemplo: Los encuestados que respondieron sobre su estado civil “Soltero” no deberían haber respondido la pregunta “Actividad del / la conyugue”.
– Nivel de representatividad: Se realiza un recuento del número de respuestas obtenidas en cada variable. Si el número de preguntas no contestadas es muy elevado, se puede asumir igualdad entre las respuestas y las no respuestas o bien, realizar una imputación de la no respuesta.
Te invito a leer: Claves para optimizar la calidad de la información en tus encuestas online.
Técnicas de Imputación
Esta técnica consiste en sustituir los valores perdidos por valores o respuestas válidas mediante una estimación de éstas. Existen tres tipos de imputación:
– Imputación aleatoria: Este tipo de imputación asume la falta de información a la aleatoriedad de la muestra. Para realizar la imputación, se analiza la probabilidad de cada valor que aparece en la variable (válidos y perdidos), y se le asignará a cada valor perdido aquellos que tengan una probabilidad igual o menor a esa probabilidad.
Ejemplo: La probabilidad de aparezca el valor A es de 0,012 (1,2%), mientras que la probabilidad del valor B es de 0,357 (35,7%). Por lo tanto los valores perdidos que tengan una probabilidad igual o menor a 0,012 se les asignará el valor A, mientras a las que tengan una probabilidad mayor que 0,012 y menor a 0,369 ( la suma de probabilidad A: 0,012 y la probabilidad B: 0,357), se les asignará el valor B.
– Imputación “Hot Deck”: En este caso, se asume que los valores perdidos no se deben a la aleatoriedad. Para realizar la imputación, se debe buscar las correlaciones entre las variables relacionadas y las variables a imputar, por lo que se usarán valores más cercanos a la variable relacionada.
Ejemplo:
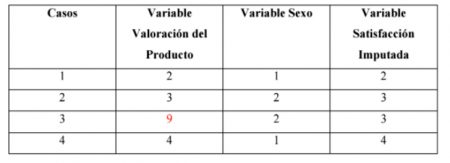
Como en la variable “Valoración del Producto” hay un valor perdido, se substituye este valor por el valor más cercano, teniendo en cuenta que existe correlación entre las variables “Valoración del producto” y “Sexo”.
– Imputación de la media de subclases: Este proceso de imputación guarda cierta similitud con el método “Hot Deck”, pero su uso se centra principalmente en variables continuas o de intervalo. Para poder realizar la imputación, se buscan dos variables que tengan correlación con la variable a imputar, y se calcula la media en cada intervalo de la variable continua, por lo que es la media la que se imputa a los valores perdidos. Sin embargo, este tipo de imputación tiende a disminuir la Desviación Típica o Estándar, por lo que afectaría a los resultados finales del análisis.
Quizá te interese leer: Razones para utilizar variables personalizadas en una encuesta online.
Conclusiones
Aunque las distintas técnicas de Depuración e Imputación pueden ser útiles para nuestro análisis estadístico, puede introducir sesgos no deseados en el resultado final, ya que no reflejan los datos reales, más bien una estimación de éstos. Es por ello que durante el diseño de encuestas, te ayudará a evitar el riesgo de no obtener respuestas u obtenerlas de manera parcial. La realización de una prueba piloto o pre-test antes de aplicar la encuesta puede ayudar a detectar posibles fallos y optimizar los resultados de nuestra encuesta.
Bibliografía
- LITTLE and RUBIN (2002) “Missing-Data Imputation” Pág: 529- 543 en: Columbia Statistics. Columbia University.
- SANCHEZ CARRIÓN J.J. (2005) Manual de análisis estadístico de datos. Pág 269- 280. Alianza Editorial.

¡COLABORA CON NOSOTROS!
En QuestionPro necesitamos tu talento, si quieres colaborar en nuestro blog da click aquí
Autor:
Sociólogo especializado en Estudios de mercado, Desarrollo Local y Cooperación al Desarrollo.



