Want to use MaxDiff analysis to make decisions? Understand consumer expectations about a product and learn to create a MaxDiff survey to model the importance of the attributes related to a product. Use anchored maxdiff scaling to identify the relative value of attributes.
MaxDiff analysis is also known as the Maximum Difference Scaling or Best-Worst Scaling. It is an analytic approach used to determine survey respondents’ preference scores for different items. MaxDiff analysis is similar to the conjoint analysis in many ways. However, the only visible difference is that MaxDiff is easier to use and is more comprehensive when you want to analyze critical research situations.
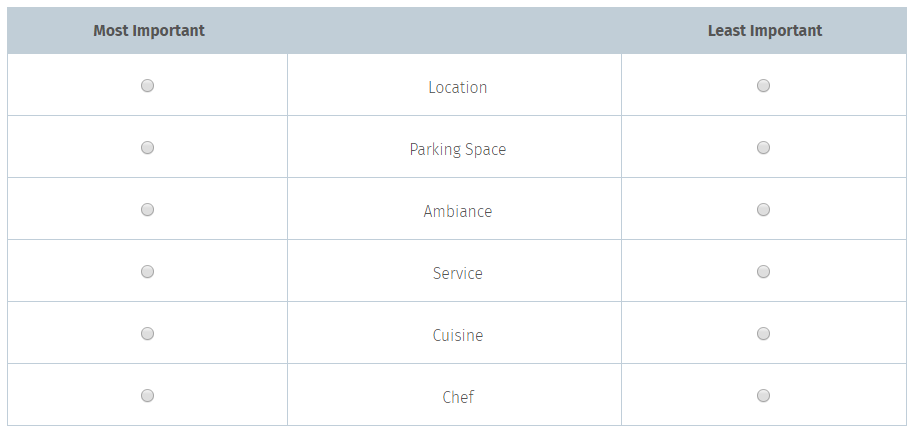
Message testing, customer satisfaction, brand preference, and product features are the typical surveys where researchers use MaxDiff analysis to predict outcomes. Maximum Difference Scaling or MaxDiff question involves the ‘Best’ and ‘Worst’ scales in a given set. Researchers ask the respondents to pick the most and least important factors in given answer options.
To understand the absolute importance of attributes in MaxDiff, you can use anchored MaxDiff scaling in your survey. With the addition of a simple question, you can derive the fundamental importance of features in your survey.
Uses of MaxDiff
MaxDiff is a useful tool in market research that helps researchers understand people's preferences. It is widely used in different fields to gain valuable insights into what people like. Researchers use MaxDiff for:
Risk Management: MaxDiff helps evaluate and prioritize risks, leading to the creation of better strategies for reducing risks and focusing on security.
Security Policy: MaxDiff helps in evaluating the effectiveness of various security policies, allowing organizations to customize their strategies according to the perceived importance of each policy component.
Organizational Security: It's important to know which parts of organizational security are most vital. MaxDiff helps identify the main areas that need focus and resources.
Asset Management: MaxDiff is used to rank assets according to their importance, making it easier to allocate resources for protecting assets in a strategic and efficient manner.
HR Security: MaxDiff analysis helps determine how important different security measures are for HR, ensuring a well-rounded approach to protecting human resources in a company.
Physical and Environmental Security: It's important to focus on physical and environmental security. MaxDiff helps identify the most important factors for planning security effectively.
Cloud Computing: MaxDiff simplifies the evaluation of user preferences and concerns regarding cloud computing services. This allows organizations to customize their offerings according to what users find most important.
Communications and Operations Management: MaxDiff assists in determining the importance of various aspects of communication and operations, helping organizations enhance their management strategies.
Access Control: Evaluating access control measures is crucial for keeping an organization secure. MaxDiff analysis helps pinpoint the most effective and important elements for strong access control.
Incident Event and Communications Management: MaxDiff improves the prioritization of incident responses and enhances effective communication strategies during events, leading to a more resilient and responsive approach.
Business Continuity and Disaster Recovery: MaxDiff helps identify the essential elements of business continuity and disaster recovery plans, assisting organizations in creating stronger and more resilient strategies.
Compliance: It's important for organizations to know which compliance requirements matter most. MaxDiff helps prioritize efforts to meet the most important standards.
Privacy: MaxDiff is used to determine how important different privacy measures are, helping organizations create strong strategies for protecting privacy.
Documentation: It's important to figure out what documentation needs are most important for good governance. MaxDiff helps identify the key aspects of documentation that are crucial for keeping thorough records.
MaxDiff example
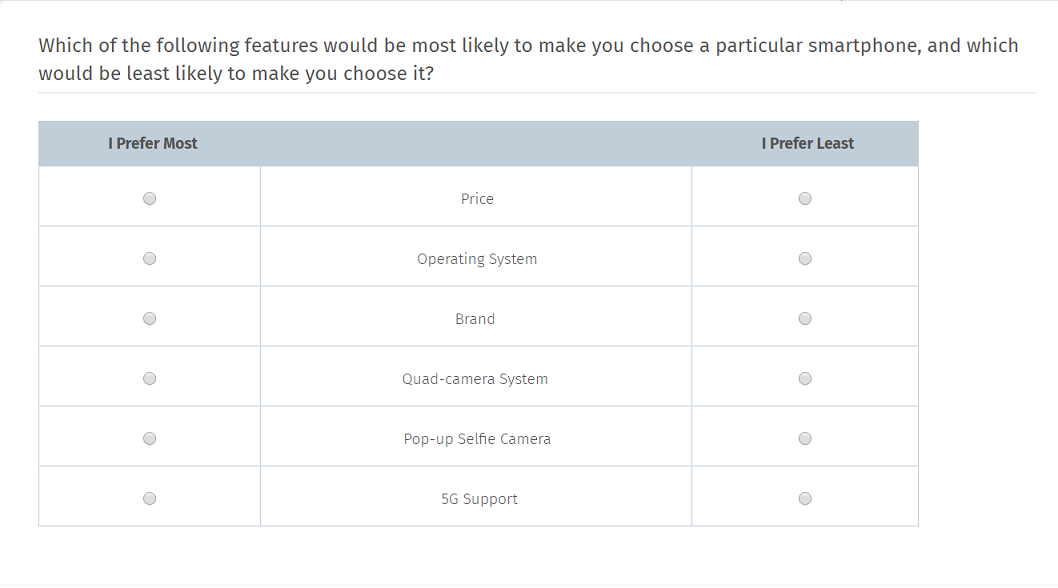
A smartphone-making company is interested in launching a new smartphone. However, before launching the new phone, they are interested to understand what features prospective customers are looking for. MaxDiff analysis helps researchers prioritize features that impact the customers' buying decisions.
The company conducts a MaxDiff survey to understand the must-have features and to know the features that will make a difference. Suppose a smartphone-making company has detailed knowledge of how customers perceive their preferences or attributes. They can create smartphones with a wide range of valuable features for the customer.
Benefits of MaxDiff analysis
MaxDiff analysis is beneficial in marketing research as it helps researchers understand customers' preferences and priorities. Here are some key advantages of using MaxDiff analysis:
Powerful discrimination: MaxDiff analysis is really good at telling the difference between items or characteristics, giving a detailed insight into how important they are compared to each other. This strong ability to distinguish helps researchers find subtle variations in preferences among survey participants.
Easier to respond: MaxDiff surveys are easier for participants to complete compared to other complicated surveys. The survey design simplifies the choices for respondents, reducing the mental effort required and leading to more accurate and efficient answers.
Test a larger number of items: MaxDiff enables researchers to assess a greater number of items at the same time. This flexibility is especially useful when evaluating numerous product features, service attributes, or marketing claims.
Eliminate scaling bias: MaxDiff analysis is useful for removing any bias in the way we scale things, which can happen with regular rating scales. Instead of absolute ratings, MaxDiff looks at how things compare to each other, giving us a stronger and fairer measure of the importance of each item in the group.
Allows diversity: MaxDiff works well with a variety of items, making it great for understanding preferences across multiple attributes. This adaptability is important for grasping the intricacies of consumer choices and preferences in various markets.
Get precise ratio data: MaxDiff findings can be converted into exact ratio data, making it easier to compare items more accurately. This improves our understanding of the results and helps in making well-informed decisions using quantitative insights.
Implements tradeoff: MaxDiff methodology involves making choices between items, which reflects real-world decision-making situations. This approach offers a more realistic picture of customer preferences because participants need to make trade-offs.
Brand preference: MaxDiff analysis is a helpful tool for figuring out which brands people prefer. Researchers can use it to learn how customers rank and see various brands, which can help in developing and positioning brands more effectively.
Customer satisfaction: MaxDiff analysis helps businesses gain a better understanding of what customers like and dislike the most. This information is crucial for companies looking to improve their products or services to meet customer needs better.
Standard MaxDiff terms
Before explaining how to use MaxDiff questions, you must get acquainted with the standard terms of the MaxDiff analysis question.
Attribute: It is an individual statement that researchers like to rank.
Set: It is a group of attributes. Researchers have the liberty to determine the size and number of characteristics in a set displayed to the MaxDiff respondents.
In MaxDiff surveys, researchers display a set of attributes and ask respondents to choose the ‘most’ and ‘least’ items in the features.
MaxDiff survey example
Here is a MaxDiff example created using our online survey platform. In the adjoining steps, you will understand how to use a MaxDiff question in your online survey.
Go to Surveys >> + New Survey
Enter the survey name and press Create Survey button
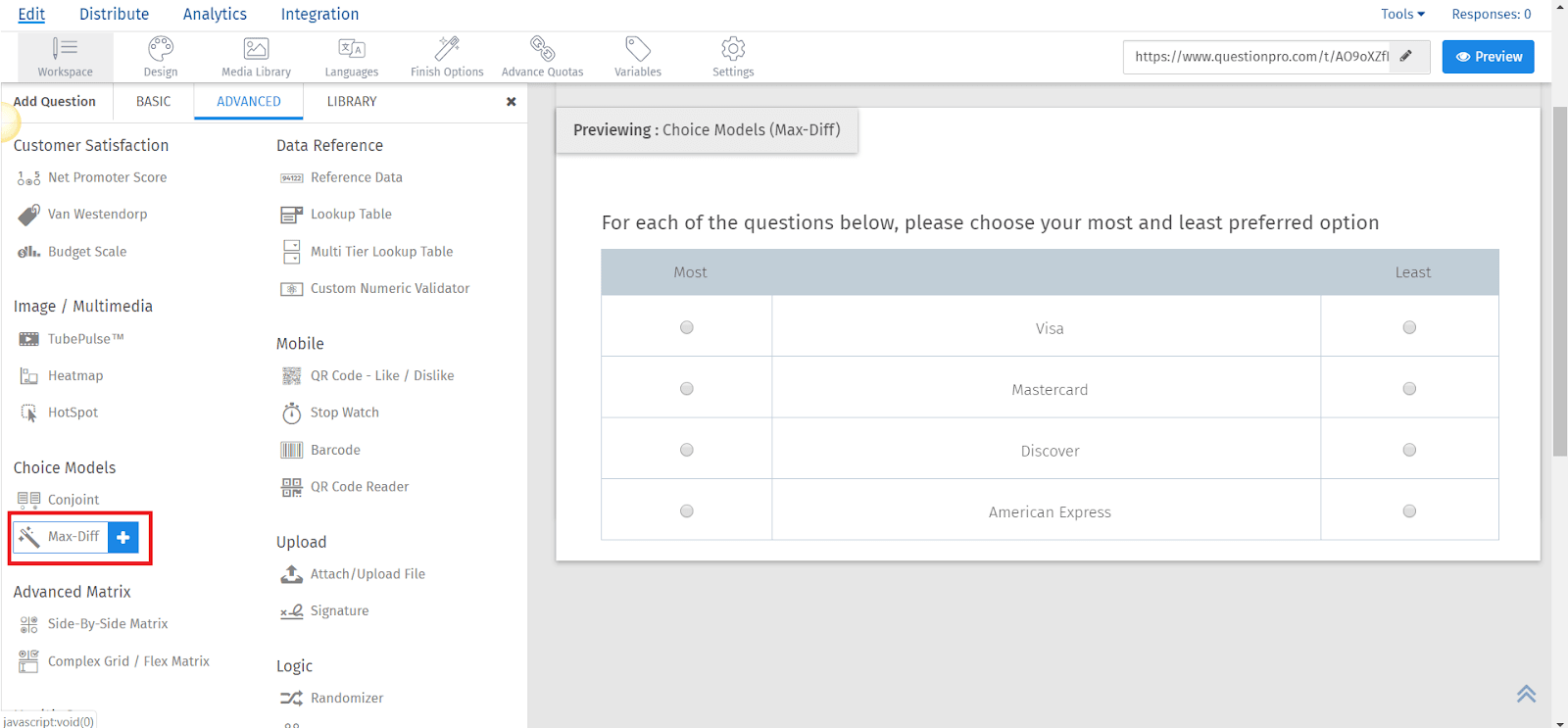
Hit the Add Question button
Go to the Advanced tab and select the Max-Diff question type
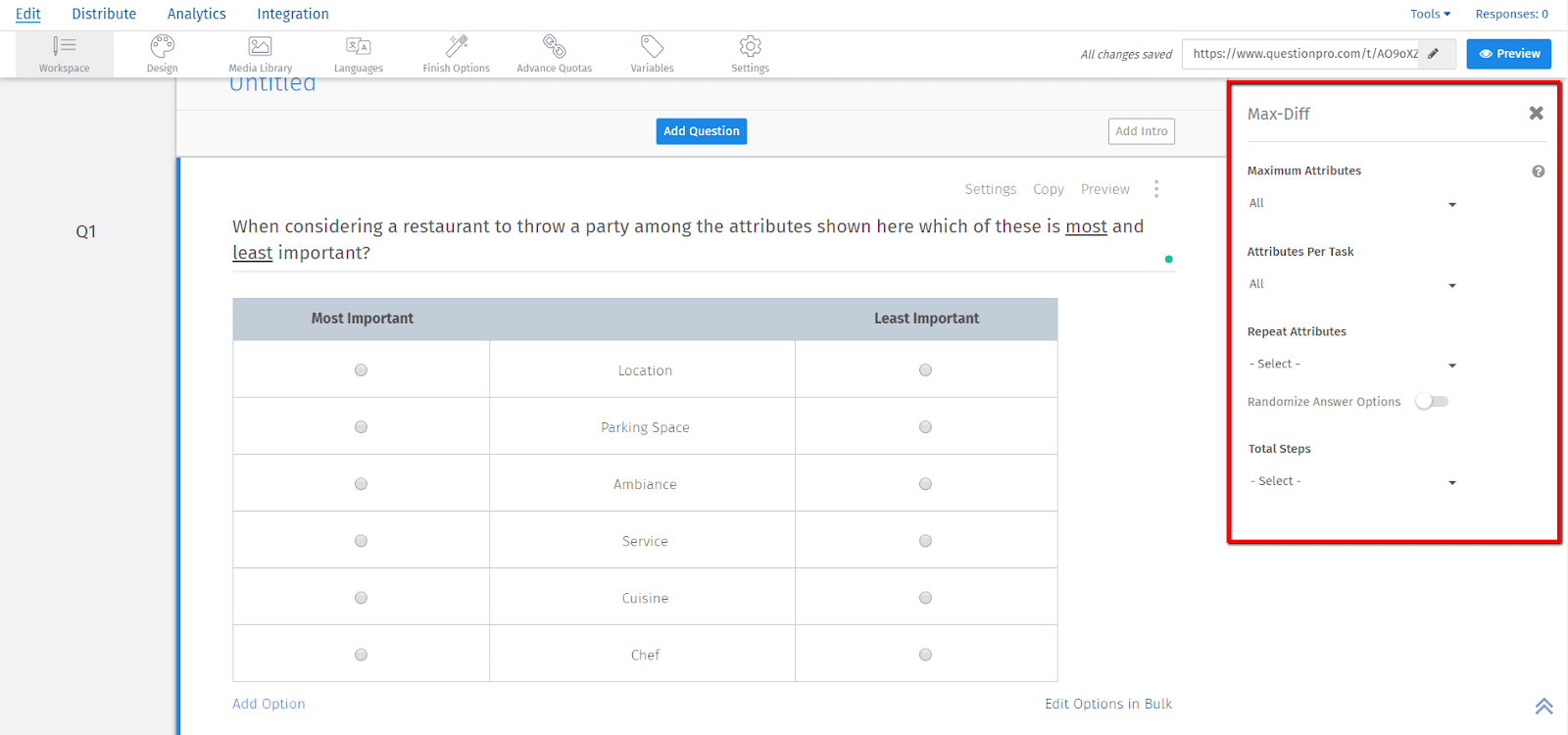
Enter the question and add the attributes by going to Edit Options in Bulk.
Go to the Settings tab at the upper right-hand corner.
Here, you can select the maximum attributes you want to be displayed. You can decide on several attributes per task and also choose the attributes you wish to repeat. Additionally, you can also select whether you want to randomize the attribute display or not.
The number of task counts shown to each respondent is based on the total number of attributes tested and the number of points you wish to display.
You can preview the question by pressing the Preview button present at the top right-hand corner.
Test the MaxDiff survey multiple times until everyone is satisfied. A well-tested survey assures you that the data you will be collecting is of value.
MaxDiff analysis example
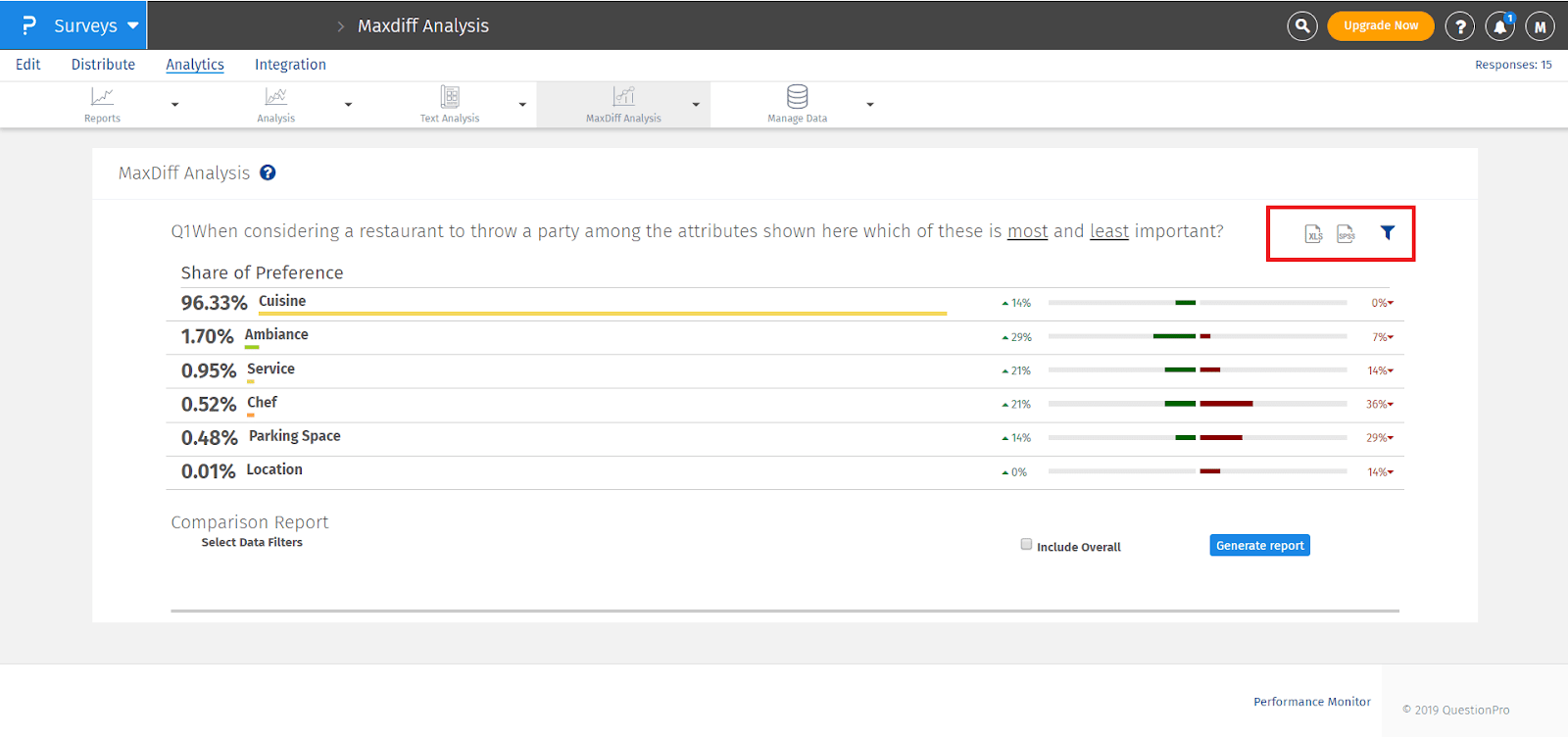
After conducting the MaxDiff survey, it is time to analyze the collected data.
MaxDiff analysis as a whole helps you understand why most of the respondents prefer a few attributes most and a few attributes least.
Go to Analytics >> Choice Modelling >> MaxDiff Analysis
In the above MaxDiff analysis example, you will find a red square at the upper right-hand corner with three icons in it.
Download the report in excel format by clicking on the XLS icon present at the upper right-hand corner.
Download the report in SPSS Format by clicking on the SPSS icon placed beside the XLS icon.
You can set filters to generate data specific to your needs by clicking on the Filter icon placed beside the SPSS icon.
Dashboard customization for MaxDiff analysis
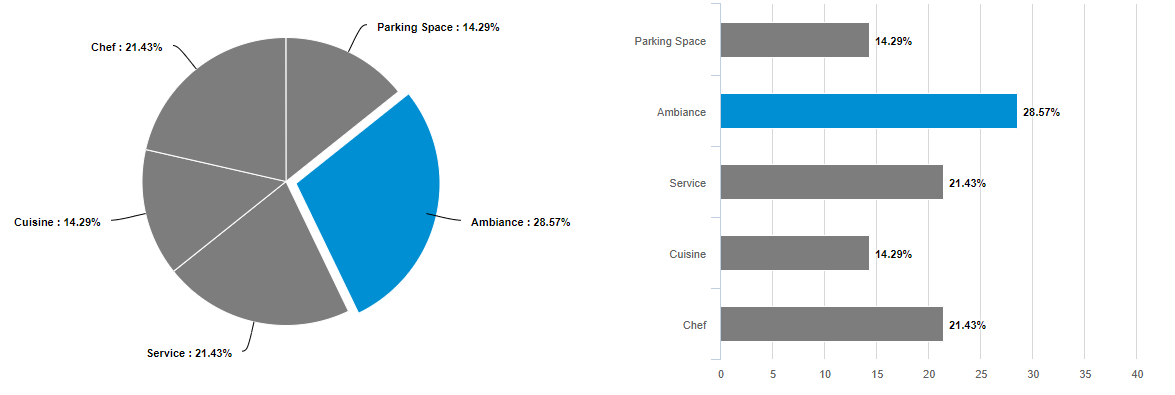
Go to Analytics >> Dashboard >> scroll down
Go to the Chart Types icon placed at the upper right-hand corner
Choose the type of chart in which you want to display the results
You can display the MaxDiff analysis in Pie, Column, Bar, and line charts
MaxDiff analysis vs. standard rating scale questions
Researchers have found that rating questions are susceptible to user scale bias, scale meaning bias, and lack of discrimination. Additionally, ranking questions have limitations of their own, like being biased, difficult for respondents to evaluate, limitations in testing the number of items, ordinal data obtained limiting the analysis, and not allowing ties.
Constant sum questions also have the same limitations and loopholes. Furthermore, researchers have seen that when presented with constant-sum questions, respondents try to make the task of evaluating all the items easier by engaging in response strategies.
Having understood the problems and limitations of different survey question types, especially with rating scale questions, researchers prefer to use the Maximum Difference Scaling or MaxDiff survey, as we call it. We can perceive MaxDiff analysis as a trade-off analysis technique allowing researchers to conduct multiple pairwise comparisons.
By effectively using the MaxDiff survey question, researchers could ask the respondents to select the most and least preferred or important points from the given list of answer options they are interested in testing for the most remarkable difference amongst items.
If we compare the MaxDiff and standard rating scale questions, then the MaxDiff question will show more significant discrimination amongst items and between responses received for the items.
In a typical MaxDiff analysis example, you will notice how easy it is to apply a robust trade-off technique compared to other rating scale questions.
Compared to the rating scale questions, the resulting item score is easy to interpret in the MaxDiff survey as it is placed on a standard scale of ‘0’ to ‘100’ points and summed up to 100.
Being simple to understand and easy to reply even for adults and kids, a MaxDiff survey yields more reliable data.
In a MaxDiff survey, you directly ask respondents to choose and not express their strength or preference using a numeric scale. Hence, there is no scope for scale use bias.
Look at the above image, and you will understand the primary difference between a rating scale question and a MaxDiff question.
In the first image, you will see a straight line response. Usually, when respondents are in a hurry, they feel everything is essential and leave such a reply. Do you think it is possible to derive any actionable data from this response?
On the contrary, the second image shows the response to a MaxDiff survey. Here, you will find that respondents have no choice but to give an unbiased preference, which is an actionable data.
CREATE, SEND & ANALYZE YOUR ONLINE SURVEY COMPLETELY FREE
 Survey Software
Easy to use and accessible for everyone. Design, send and analyze online surveys.
Survey Software
Easy to use and accessible for everyone. Design, send and analyze online surveys.
 Research Suite
A suite of enterprise-grade research tools for market research professionals.
Research Suite
A suite of enterprise-grade research tools for market research professionals.
 Customer Experience
Experiences change the world. Deliver the best with our CX management software.
Customer Experience
Experiences change the world. Deliver the best with our CX management software.
 Employee Experience
Create the best employee experience and act on real-time data from end to end.
Employee Experience
Create the best employee experience and act on real-time data from end to end.