For example, if you wanted to ask users their Zip Code and wanted to validate (to make sure that the data entered is correct) against the standard US Postal Service Zip Code database, you can use the Reference Data question survey type for this.
Researchers don’t have to spend time to validate every zip code entered using this research method. The tool prompts the respondent to enter the correct zip code in case of a typo or an error. It matches the input against the master data. The researcher needs to specify in the back end the country who’s zip code he/she wants to collect, and the tool does the rest. It helps eliminate fake, inconsistent, and straight-line answers, and promotes data segregation for better analysis later.
Uses of reference data questions
Researchers must use the data reference question to capture valid zip codes from respondents. This question is one way to identify whether the respondents are unique or not. The zip code can be checked against another item (for example: specify your location) and matched to ensure no discrepancy. In general, it is a fool-proof way of collecting a response due to the validation applied.
Example of a reference data question
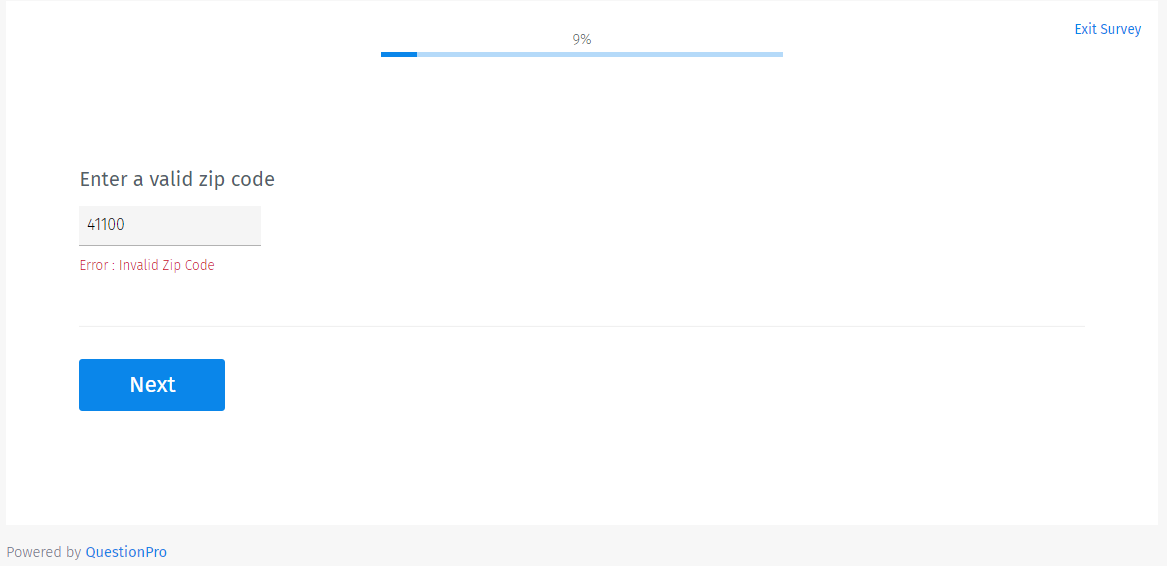
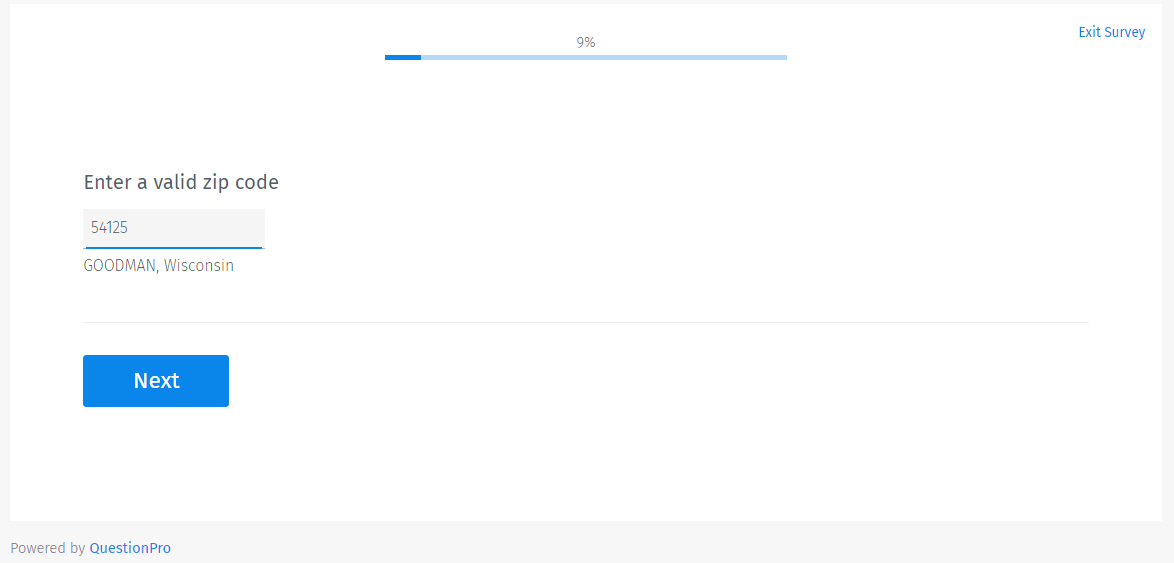
Let’s take the case of a car insurance company that’s researching car buyers in the US. Car insurance rates differ by zip codes. To get a complete understanding of the market and in the interest of the quality of the study, the researching agency can use this question to validate the answers coming in from respondents and control the quality of the responses by weeding out poor quality or fake responses. If the respondent enters a wrong zip code, the survey research tool flags this response and prompts the user to type in the correct zip code.
Example of wrongly entered zip code:

Example of a correctly entered zip code:
Advantages of using reference data questions
Here are the advantages of using a dynamic multi-tier lookup table:
Easy to implement: The question-type is simple to implement. The researcher needs to choose the country while setting up the question, and the tool does the rest.
Easy to analyze: The data captured will be in a standard format, free from typos and alphabet characters, which makes it very easy to analyze and interpret.
Accuracy: There is no room for errors as the tool prompts the respondents to type in a valid zip code if it senses a valid code entered.
Quality: Topmost data quality is maintained because the tool does not allow respondents to fill in unusual or fake responses randomly.
How to use the reference data question
To learn how to use this survey feature, check out our help file on reference data survey questions.
 Survey Software
Easy to use and accessible for everyone. Design, send and analyze online surveys.
Survey Software
Easy to use and accessible for everyone. Design, send and analyze online surveys.
 Research Suite
A suite of enterprise-grade research tools for market research professionals.
Research Suite
A suite of enterprise-grade research tools for market research professionals.
 Customer Experience
Experiences change the world. Deliver the best with our CX management software.
Customer Experience
Experiences change the world. Deliver the best with our CX management software.
 Employee Experience
Create the best employee experience and act on real-time data from end to end.
Employee Experience
Create the best employee experience and act on real-time data from end to end.