




Good data leads to better decisions. But when your data is full of errors, duplicates, or missing information, it can cause mistakes, waste resources, and frustrate your customers. That’s where data quality tools come in.
These data quality solution tools help you clean, check, and organize your data so it’s accurate, consistent, and ready to use, no matter how much of it you’re working with.
In this article, we’ll describe and explain 7 of the best data quality tools available today. You’ll learn what each one does, why it’s useful, and where it might fit into your business. We’ll also give you some practical tips on how to choose the tool that’s right for your needs, so you can trust your data and use it with confidence.
What are Data Quality Tools?
Data quality tools are software solutions that help make sure your data is accurate, consistent, and reliable. They work by checking your data for errors, fixing issues, and keeping everything in the right format so it’s easy to use across your business.
Some of their core functions include:
- Profiling: Scanning your data to understand its structure, patterns, and potential problems.
- Cleansing: Correcting mistakes like typos, missing fields, or outdated information.
- Validation: Making sure data follows the rules you set, such as valid email formats or correct date ranges.
- Deduplication: Finding and removing duplicate records so you don’t have the same information stored twice.
- Enrichment: Adding extra details from trusted sources to make your data more complete.
In today’s world, the right data quality tool is a key part of the modern data management stack.
They often work alongside databases, data warehouses, CRM platforms, and analytics tools to keep information in top shape. By improving data quality at the source, they help every department from marketing to finance work with accurate, trustworthy insights.
7 Best Data Quality Tools for Better Research Data
Clean, reliable data is essential for producing accurate research results. The following tools help researchers ensure their datasets are accurate, consistent, and ready for analysis.
1. QuestionPro
QuestionPro is a powerful survey and research platform with built-in data quality features, including fraud detection, duplicate prevention, geo-location checks, and custom response validation. It is designed to help researchers ensure they work only with clean, verified responses before moving to analysis.

Features:
- Data Cleansing feature for data cleaning.
- Duplicate prevention for unique, valid responses.
- Custom response validation rules to match research requirements.
- Advanced analytics, including max-diff and NPS, for deep insights into collected data.
- Multi-channel survey distribution options.
- Identifies gibberish words from responses.
- Integration with popular CRM, BI, and analytics platforms.
Limitation:
- Some advanced features may require training to fully utilize.
Pricing:
- Paid plans start at $99 per month, with custom enterprise pricing available for organizations with specific needs.
2. Ataccama ONE
Ataccama ONE combines data quality, data governance, and master data management into one AI-powered platform for enterprise research teams.
Features:
- Automated data profiling and cleansing.
- Master data management for consistent records.
- AI-assisted anomaly detection.
- Data cataloging and governance tools.
- Real-time monitoring of data quality.
Limitation:
- It may be overkill for small or mid-size research teams.
- Implementation can require significant setup time.
Pricing:
- Custom pricing based on organization size and use case.
3. Informatica Data Quality
Informatica Data Quality is an enterprise-grade solution with automation, real-time monitoring, and AI-powered matching to keep research data clean and consistent.
Features:
- AI-driven data matching and deduplication.
- Real-time data quality monitoring.
- Automated cleansing and validation rules.
- Address verification and standardization.
Limitation:
- Pricing may be high for smaller teams.
- Steeper learning curve for non-technical users.
Pricing:
- Custom pricing based on business size and requirements.
4. IBM InfoSphere QualityStage
IBM InfoSphere QualityStage is known for its powerful matching and deduplication capabilities, making it ideal for large-scale research data projects.
Features:
- Data standardization and validation.
- Advanced matching algorithms for deduplication.
- Support for complex, multi-source data integration.
- Data profiling and monitoring tools.
Limitation:
- High complexity may require dedicated technical staff.
- Pricing is on the higher end.
Pricing:
- Custom enterprise pricing available from IBM.
5. Talend Data Quality
Talend Data Quality offers a versatile platform for data profiling, cleansing, and enrichment, with strong integration capabilities for research databases and data pipelines.
Features:
- Data profiling to assess quality and identify issues.
- Cleansing and standardization for accurate datasets.
- Data enrichment from external sources.
- Duplicate detection and merging.
- Integration with Talend’s data integration and cloud services.
Limitation:
- May require technical expertise for advanced configurations.
- Large-scale processing can demand high system resources.
Pricing:
- Talend offers paid enterprise plans, with pricing based on deployment and feature needs.
6. Trifacta Wrangler
Trifacta Wrangler provides a user-friendly interface for data wrangling, profiling, and preparation without requiring heavy coding skills.
Features:
- Interactive data cleaning and transformation.
- Data profiling and quality checks.
- Machine learning suggestions for transformation tasks.
- Integration with cloud data warehouses and analytics platforms.
- Support for large datasets and multiple file formats.
Limitation:
- Some advanced features require premium plans.
- Best suited for structured datasets.
Pricing:
- Paid pricing plans are available upon request.
7. OpenRefine
OpenRefine is a free, open-source tool perfect for cleaning and transforming messy datasets, making it a favorite for researchers with budget constraints.
Features:
- Data exploration and profiling.
- Batch editing and transformation of data.
- Integration with external data sources.
- Flexible filtering and faceting options.
- Support for large datasets.
Limitation:
- Limited automation features compared to paid tools.
- No built-in real-time validation or monitoring.
Pricing:
- Free and open-source.
By choosing the right data quality tool, you can ensure your research is built on accurate, trustworthy data from the start.
You can also learn about the best data collection tools for research.
How to Choose the Right Data Quality Tool
Choosing the right solution starts with understanding your assets and your teams. The best data quality tools don’t just fix problems after the fact; they provide continuous monitoring of data so you’re always working with good data.
1. Check the Breadth of Data Quality Checks
Look for a platform that has data quality checks to flag duplicate entries, incomplete records, and suspicious patterns before they impact your results. Features like duplicate detection, response validation, and pattern recognition are key to catching data quality issues early.
2. Prioritize Data Discovery and Governance
Strong discovery and governance work together to keep your data accurate and trusted over time.
Features like:
- Discovery to explore, profile, and understand datasets at every stage.
- Governance to keep consistency, security, and compliance across systems.
Together, this means your data remains accurate, secure, and reliable.
3. Use Data Observability and Testing
A good tool should have data observability so you can see anomalies in real time. Automated testing and validation ensure every response or record meets your requirements, reducing manual review work for your team.
4. Make it Seamless with Your Data Platform
Your chosen solution should integrate with your existing platform, so your teams can manage workflows without disruption. This means data quality checks are part of your daily workflow, not an afterthought.
5. Focus on Continuous Improvement
A good tool should improve data and save time by automating checks. Features like:
- Duplicate detection to remove duplicates.
- Validation rules to ensure responses meet requirements.
- Response verification to confirm accuracy.
Integration with your existing platform means seamless workflows across teams and projects. By combining prevention with intelligence, you can stop bad data from entering your system, and every decision is based on accurate information.
Choosing the right tool is more than just checking boxes; it’s finding a platform that actively protects and elevates your data from collection to analysis.
When your solution brings together automated prevention, real-time monitoring, and actionable insights, your teams can work with confidence knowing every decision is based on good data.
Comparing Tools to Help You Choose the Right One
With so many top data quality tools available, it can be tricky to know which one fits your needs best.
| Tools | Key Features | Cons | G2 Ratings (Out of 5) | Pricing |
| QuestionPro | Data cleansing, duplicate prevention, custom response validation, advanced analytics, multi-channel distribution, gibberish word detection, CRM/BI integration. | Some advanced features may require training | 4.5 | Starts at $99/month. |
| Talend Data Quality | Data profiling, cleansing, standardization, enrichment, duplicate detection/merging, and integration with Talend services. | Requires technical expertise, resource-heavy for large datasets | 4.3 | Custom enterprise pricing. |
| Informatica Data Quality | AI-driven matching/deduplication, real-time monitoring, automated cleansing/validation, and address verification. | High cost, steep learning curve | 4.5 | Custom pricing. |
| OpenRefine | Data exploration, profiling, batch transformation, external data integration, flexible filtering, and support for large datasets. | Limited automation, no real-time validation | 4.6 | Free and open-source. |
| Ataccama ONE | Automated profiling/cleansing, MDM, AI anomaly detection, data cataloging/governance, and real-time monitoring. | Overkill for smaller teams, long setup | 4.2 | Custom pricing. |
| IBM InfoSphere QualityStage | Standardization, advanced matching, deduplication, profiling, and multi-source integration. | Complex setup, high cost | 4.1 | Custom enterprise pricing. |
| Trifacta Wrangler | Interactive data cleaning/transformation, profiling, quality checks, ML transformation suggestions, cloud integration, and large dataset support. | Premium features require higher-tier plans | 4.3 | Paid pricing upon request |
The best tool for you will depend on your data workflows, team size, and the level of automation and integration you need.
Whether you’re looking for an all-in-one solution with advanced data quality checks or a specialized platform for large-scale data validation, this comparison can help you make a confident, informed choice.
Benefits of Using Data Quality Tools
Using the right data quality tools can have a big impact on how your organization works and the results you achieve. Here are some of the key benefits:
- Improved decision-making accuracy: Reliable, well-structured data helps teams make confident, fact-based decisions.
- Increased operational efficiency: Automated data quality checks save time, reduce manual errors, and streamline workflows, ultimately enhancing overall productivity.
- Better compliance and risk management: Strong data governance ensures you meet regulatory standards and avoid costly mistakes.
- Higher customer satisfaction and personalization: Accurate, up-to-date information allows for more tailored interactions and better customer experiences.
When data is clean, consistent, and trustworthy, every part of your business, from strategy to customer engagement, can perform at its best.
Why QuestionPro Can Be The Best Choice for Maintaining Data Quality
When it comes to ensuring high-quality data, QuestionPro stands out by combining powerful survey and research capabilities with built-in data quality checks that prevent problems before they impact results.
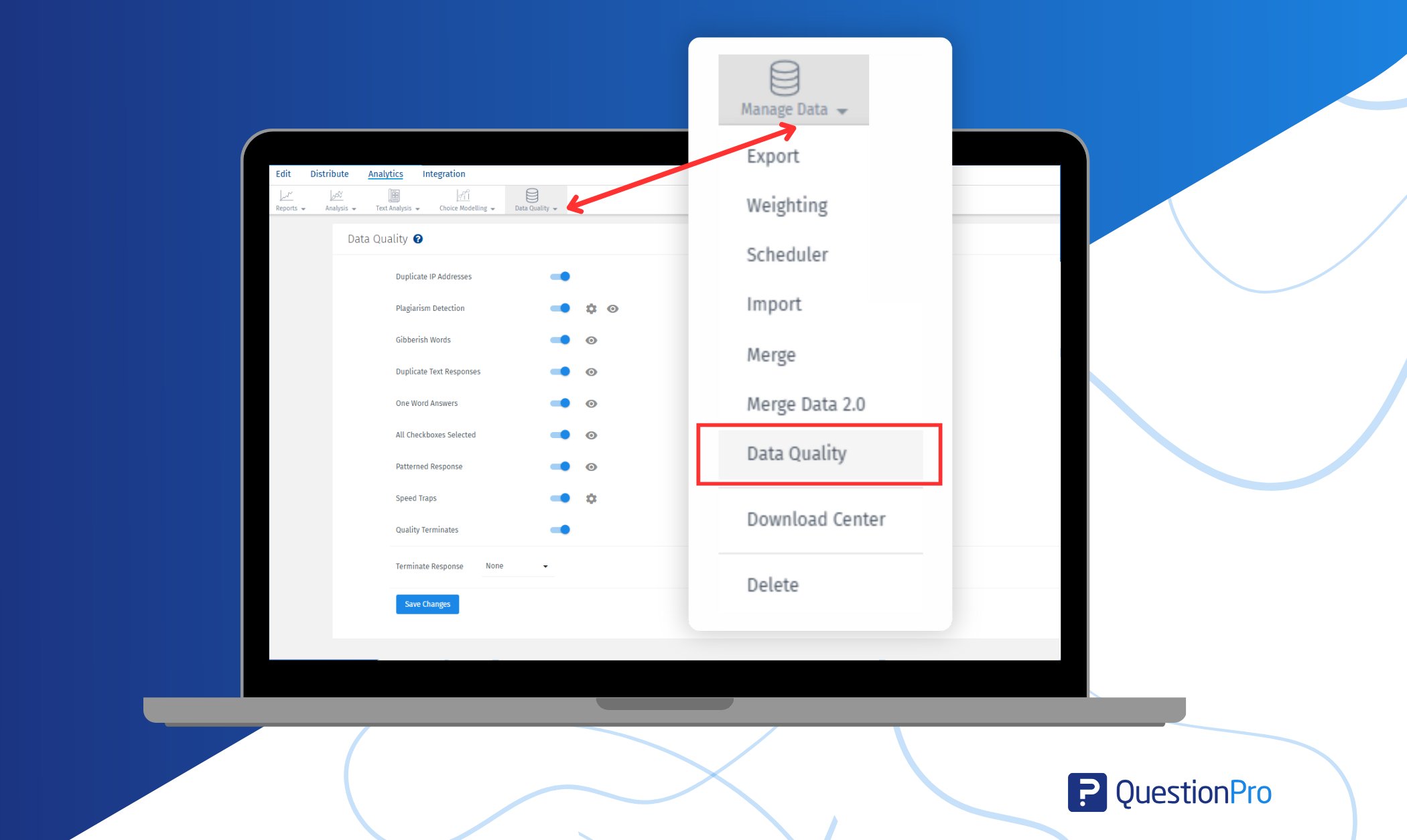
It’s not just a data collection tool; it’s a full solution for monitoring data quality, improving data reliability, and keeping your data pipeline clean from start to finish.
Key strengths include:
- Duplicate IP detection and duplicate text responses prevention to avoid repeated or fraudulent submissions.
- Speed traps and patterned response detection to flag low-effort or automated entries.
- Gibberish word identification and one-word answer flags to maintain response quality.
- Custom response validation to ensure data meets your specific research requirements.
- Standardization tools to keep formats consistent for easier analysis.
- Timeliness checks to make sure you’re working with the most up-to-date information.
- Advanced analytics like MaxDiff and NPS to uncover deep insights from your collected data.
- Integration with popular CRM, BI, and analytics platforms to streamline workflows and keep your data connected.
- Save time with flexible logic and advanced filters that help you quickly refine, segment, and validate responses for better decision-making.
Because QuestionPro integrates with popular CRM, BI, and analytics platforms, data professionals can easily move from data discovery to analysis without losing quality along the way. This makes it a reliable choice for organizations that want to standardize data, protect sensitive data, and build a strong foundation for decision-making.
Best Practices for Maintaining High Data Quality
Keeping data assets clean and reliable requires a combination of the right tools, processes, and team alignment. Here are some best practices to help you maintain data quality and support data quality assurance across your organization:
- Continuous monitoring and audits: Regular data monitoring helps identify and resolve issues early, ensuring ongoing data integrity and data security.
- Clear data governance policies: Well-defined rules guide data users in managing, storing, and accessing information across the modern data stack.
- Cross-department collaboration: Collaboration between technical and business teams improves data quality processes and ensures everyone can support data quality efforts.
- Regular data testing: Periodically test data to verify accuracy, detect inconsistencies, and improve data quality before it reaches the data warehouse.
- Data validation and security checks: Put controls in place to ensure data accuracy, protect sensitive data, and maintain compliance with regulatory requirements.
By following these practices, organizations can build a sustainable framework for data quality assurance that keeps information accurate, secure, and ready for decision-making.
Also check: Data Accuracy vs Data Integrity
Conclusion
Data quality isn’t just a technical box to tick; it’s the base of trusted insights and confident decision-making. In this article, we looked at the 7 best data quality tools and how to choose the right one for your research, and best practices for using a data quality tool.
Data quality requires an ongoing effort with the right tools and processes. QuestionPro has a suite of features to detect duplicates, validate responses, and identify suspicious patterns before they impact results.
With advanced testing, real-time monitoring, and integration-friendly workflows, QuestionPro helps organizations to protect data integrity, build trust, and get the most out of their data asset management.
Frequently Asked Questions (FAQs)
Answer: Low-quality data can lead to flawed insights, wasted resources, wrong strategic moves, and damaged customer trust.
Answer: Completeness ensures all necessary information is present, while consistency means data follows the same format, rules, and standards across systems.
Answer: Data governance is the framework of policies, processes, and standards that ensure data is managed properly, reducing errors and inconsistencies.
Answer: Automation can detect duplicate entries, flag incomplete responses, validate formats, and spot suspicious patterns much faster than manual checks.
Answer: QuestionPro offers built-in data validation, duplicate detection, and response pattern checks, helping organizations protect data integrity before analysis begins.


