




Understanding the difference between synthetic data vs mock data is important for anyone who works with testing, research, or AI development. Both are used when real data is not available or cannot be shared because of privacy rules. They help teams build, test, and improve systems without using actual user information.
Synthetic data is created by computers to look and act like real data, while mock data is made up to test if things work correctly. You might use synthetic data to train an AI model and mock data to check if your form or dashboard works as expected.
In this blog, we’ll explain what synthetic and mock data mean, how they are different, and how you can decide which one fits your project best.
How Synthetic Data Works in a Survey?
Synthetic data is data made by computers instead of being collected from real people. It’s created to look and act like real survey answers, but doesn’t come from actual participants. This means you can use it safely without worrying about privacy or personal details.
In a survey, synthetic data helps you test how everything works before collecting real responses. For example, you can fill your survey with computer-generated answers to check if questions flow in the right order, if skip logic works properly, and if reports show the results clearly. It’s like a practice run that helps you spot and fix mistakes early.
Example:
Imagine you’re creating a customer feedback survey. Before sending it out, you generate fake responses to test if your survey and reports work correctly. Once everything runs smoothly, you can launch it for real participants.
Synthetic data in surveys helps you test, improve, and prepare your survey before it reaches real people. It saves time, keeps information private, and ensures your survey works exactly as you expect.
Also Read: Synthetic Dataset: What it is, Benefits + Usage
How Mock Data Works in a Survey?
Mock data is made-up information used to test a survey before collecting real answers. It helps researchers and developers make sure everything works as expected, from how questions appear to how the results are displayed. Mock data doesn’t have to be perfect or realistic; it just needs to help you check that your survey runs smoothly.
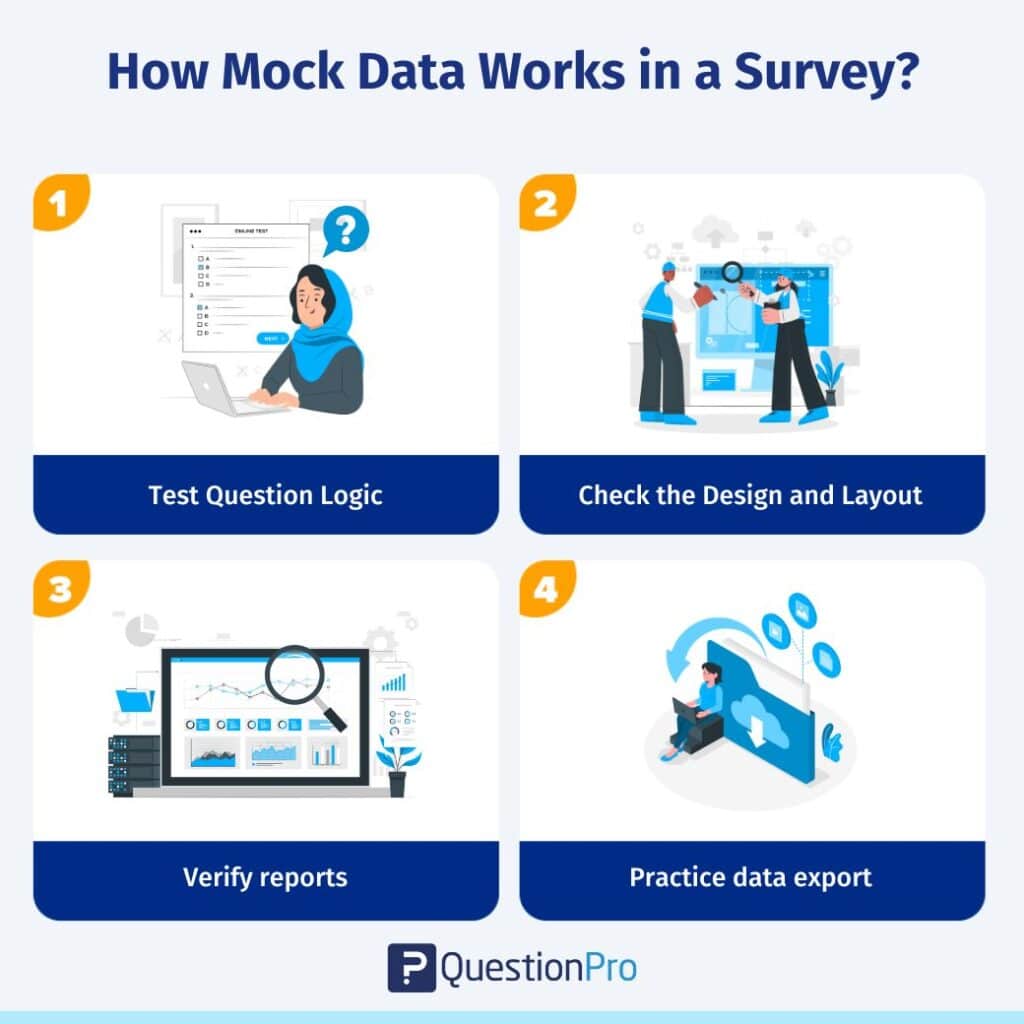
When creating a survey, mock data can be used to:
- Test question logic: Make sure skip logic or branching questions go to the right sections.
- Check design and layout: See if the survey looks clean on both desktop and mobile devices.
- Verify reports: Confirm that charts, graphs, and summaries appear correctly after responses are collected.
- Practice data export: Test how results look when downloaded into tools like Excel or analytics dashboards.
Example:
Suppose you’re designing a short employee satisfaction survey. Before sharing it with your team, you fill it with 50 mock responses to check if all questions record answers correctly and if the dashboard shows the right averages. Once everything works well, you can clear the mock data and start collecting real feedback.
What Are the Key Differences Between Synthetic Data and Mock Data?
Synthetic data and mock data might sound similar, but they serve very different purposes. Both are used when real data isn’t available or can’t be shared, yet the way they are created and applied makes them unique. Understanding these differences helps teams choose the right type for testing surveys, research, or product development.
| Aspect | Synthetic Data | Mock Data |
| Definition | Artificially created data that imitates real-world information using algorithms or AI models. | Sample or fake data created manually or with simple tools to test systems and designs. |
| Purpose | Used for realistic analysis, AI training, and simulation when real data is unavailable or restricted. | Used for testing applications, layouts, or forms before real data is available. |
| Creation Method | Generated through machine learning, simulations, or statistical models. | Created manually or with random data generators and mock APIs. |
| Realism | Very realistic and follows real-world patterns and correlations. | Basic and random; does not reflect actual data relationships. |
| Data Privacy | Protects privacy because it doesn’t use real personal information. | Protects privacy by using fake values, but not suitable for detailed analysis. |
| Data Quality | High-quality and logically consistent; can mimic real-world distributions. | Lower quality; focuses on functionality rather than realism. |
| Use Cases | AI model training, predictive analytics, research, and privacy-safe data sharing. | Software testing, UI design, demos, and prototype validation. |
| Complexity | Requires advanced tools and algorithms to generate. | Simple to create with manual input or generators. |
| Value for Analysis | High value because it can be used for realistic modeling and decision-making. | Low value for analysis; only useful for testing processes. |
| Example | A synthetic dataset that simulates hospital records for medical research. | Fake names and email addresses were used to test a sign-up form. |
Recommended Read: Synthetic Data vs Simulated Data: What’s the Difference?
Choosing Between Synthetic and Mock Data
Choosing between synthetic data and mock data depends on what you’re trying to achieve. Both types of data are useful, but they serve different goals. Both synthetic data and mock data play important, complementary roles in the survey design and research process. Respondents across industries reported using each type of data at different stages to improve testing, privacy, and performance.
Mock Data: Ideal for Survey Design and Pre-Launch Testing
A majority of respondents reported using mock data during the early stages of survey development. It helps teams validate the structure and flow of a survey without needing real responses.
According to participants, mock data is commonly used for:
- Testing skip logic, piping, and branching
- Previewing question layouts and formatting
- Ensuring input fields, validation rules, and calculations work as expected
- Generating quick prototypes for stakeholder review
Mock data offers speed and convenience, allowing researchers to iterate quickly before deploying the actual survey.
Synthetic Data: Essential for Post-Collection Analysis and Privacy Protection
Once real responses are collected, many respondents shared that they turn to synthetic data to support deeper analysis and ensure data privacy. Synthetic data is especially valued when sharing results externally or applying AI models to survey data.
Key uses reported include:
- Creating privacy-safe versions of real response data for analysis or sharing
- Training AI tools on survey results without exposing sensitive information
- Simulating respondent behavior or running what-if scenarios based on synthetic survey outputs
- Ensuring compliance with data protection regulations (e.g., GDPR, HIPAA)
Survey participants emphasized that mock and synthetic data are not interchangeable but complementary. Mock data supports fast and flexible development, while synthetic data enables secure, scalable, and insightful analysis after real data is collected.
By combining both, teams can build better surveys, test more efficiently, and analyze with confidence without compromising privacy or quality.
Conclusion
Synthetic data and mock data both play valuable roles in modern testing, research, and development. Synthetic data offers realistic, privacy-safe information that can be used to train AI models, simulate real-world behavior, or analyze complex systems without exposing personal details.
Mock data, meanwhile, is simpler and faster to generate, making it ideal for testing prototypes, validating designs, or checking functionality before real data is available. The two can even work together. Mock data helps during early testing, while synthetic data supports more advanced and reliable data analysis later on.
With QuestionPro, teams can explore both approaches easily. The platform allows users to create structured mock datasets for testing surveys or dashboards, as well as collect real data that can be transformed into synthetic versions for deeper research and modeling. This flexibility helps researchers, developers, and organizations experiment safely, test efficiently, and make better decisions based on accurate and compliant data.
Frequently Asked Questions (FAQs)
Answer: Synthetic data is generated by algorithms or AI models to mimic real-world data patterns for analysis or AI training. Mock data is made manually or with simple tools to test systems, forms, or prototypes.
Answer: Use synthetic data when your project needs realistic information that behaves like real data. It’s ideal for AI model training, data simulations, and privacy-safe testing. Use mock data when you’re only testing layouts, user flows, or system functions and don’t need real patterns or relationships.
Answer: Synthetic data can’t fully replace real data, but it’s a great alternative when real data is limited or restricted by privacy laws. It can help train AI models, test algorithms, and perform analysis without exposing sensitive information.
Answer: Generating synthetic data is completely artificial and doesn’t contain any personal or identifiable information. This makes it useful for complying with privacy regulations like GDPR or HIPAA, since organizations can analyze or share data without risking exposure of real user details.
Answer: Yes. Many teams use mock data for early testing and synthetic data later for more advanced validation. Mock data helps with design and functionality, while synthetic data adds depth, realism, and privacy protection during later testing or analysis stages.



