



Recently when giving my desk a much needed cleaning I came across an article by Jerry Thomas with the firm Decision Analyst. His white paper focused on the use of the top box as a measure for conveying scores to survey scales. The top box score is the sum of percentages for the top one, two or three highest points on a purchase intent, satisfaction or awareness scale. By ‘top’ it is assumed to be the most favorable points on the scale (most likely to recommend, re-purchase, most satisfied, etc.) It is an alternative to the use of the mean score for the scale.
The top-box as a way to present data is effective, especially when presenting to executives who don’t have the appetite to digest means and medians. However, collapsing data does comes with a cost. In the table below you can see that all three supermarkets have a top two box score of 45%. It would be misleading if you only presented this score – all three markets would be viewed as equals. However, this is clearly not the case as respondents who selected Alpha Beta would clearly disagree as 35% gave this store the highest recommendation, followed by Super Store, and then Acme. Collapsing data has its place, but the moral here in the spirit of full-disclosure, is to not bury relevant findings.
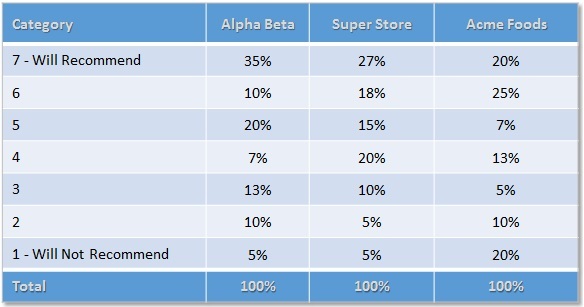
It is also relative in any discussion of top box scores to look at the bottom of the scale. Respondents choosing Acme Foods were four-times more likely to say they would not recommend the market in comparison to the other stores.
A corollary to that moral is to be prepared as the survey author and analyst in charge to dig into the data and see if there are significant deviations. For example does the top-box score vary for heavy users vs. light users, or new customers vs. existing customers? Survey data is inherently multi-dimensional and should be worked thoroughly before we use it to tell our story.
Looking to deliver exceptional customer experience? Discover more about how to delight your customer at every touchpoint and turn them into brand advocates.



