Customer churn and Net Promoter Score
NPS is a widely used methodology to measure CX. In fact, it’s nearly ubiquitous and has gained a massive following around the world - primarily because of its simplicity and equally importantly - as a measure of predicting customer loyalty - and in turn profitability.
The rate of customer attrition also know that Customer Churn is the single measurement that can sustain companies through good and bad times. However, determining and more importantly predicting Churn without a data-science team dedicated to this is nearly impossible. Most data-science teams look at _behaviours_ and try to correlate a multitude of behavioral variables to exit variables. While this is theoretically true, it almost never gives researchers the “Why” - it only gives a co-relational model - not a causational model.
Here is an enhancement to the NPS model - to include a operationally & cognitively easy way to:
- Isolate & Identify Reasons - for Churn (Root Cause) et al.
- Auto-Identification - Establish a model for dynamically and automatically updating the reasons
- Predicting Churn - based on the Reason-Identification comparisons - of Passives Vs. Detractors.
NPS Programs - Use Existing Platform/Process/Models
Exit / Cancellation Surveys
Most NPS Programs already have models in place for contacting customers after they cancel/churn and determine reasons for churn. This is post-facto and while it gives good directional indicators, operationalizing this has been challenging. This is partly because reasons change over time and there is no “Base” comparison. By base comparison, we mean that - if we are only surveying customers who are cancelling / churning - then its very difficult to map that against folks who are NOT churning - the existing customers.
Ongoing NPS / Check In Surveys
Companies that use NPS as an ongoing basis for existing customers can use that same model to determine and predict churn. The benefit of using on-going operational surveys to determine Churn is that it is already in place - the ability to deliver emails/sms notifications, post transactions and collect data.
While it’s easy to determine NPS - dynamically determining root-cause / isolating and identifying root causes has been relegated to text analytics - around “Why?”
For surveys, most text analytics models don’t work, partly because of NLP/Training data. Good Machine Learning models need a lot of training data to increase accuracy.
In this solution, we functionally determine the “Why” answer by using the collective intelligence of the customers themselves.
Isolation
The first task at hand is Isolation. By isolation, we mean determine the top one or two reasons why someone has the propensity to churn. Every product / service has some unique and key elements that determine customer affinity and inversely determine customer churn. The first key idea is to isolate these key reasons. It can’t be done using text analytics, simply because AI/NLP tools are still not good enough to determine “Weight” around different reasons from simple text.
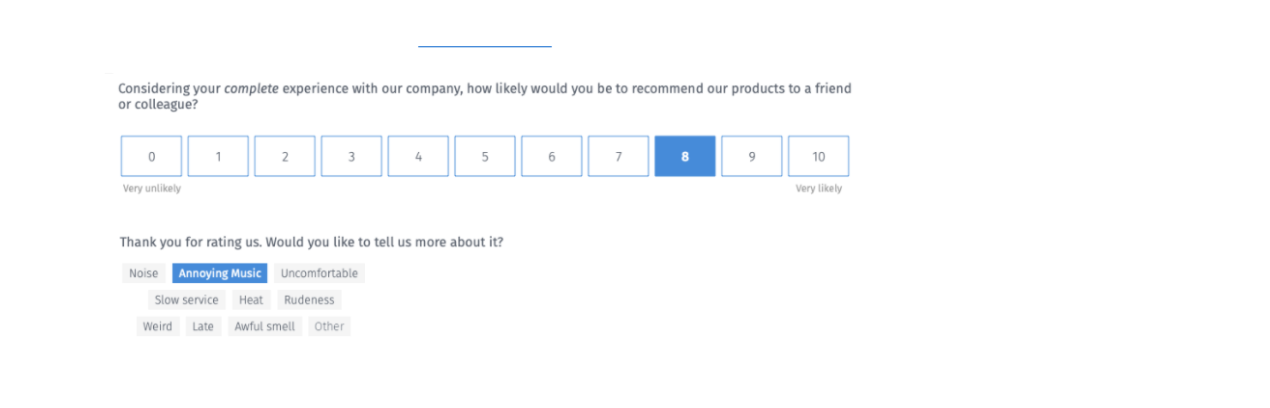
We are showcasing a much simple approach to this - we let the customer choose between a set of “reasons” when they go through an NPS survey. Here is an example below:
We allow users to choose between 1, 2 or 3 items - this is needed for isolation. There may be many reasons for churning, but we are forcing respondents to choose the “top” reasons for churn. This process allows for isolation of the reasons automatically.
Identify
The next part is concrete identification. The typical argument against using a model like this, where the reasons are pre-determined, is that these reasons may not be exhaustive. This is correct. To solve for this, we include an “Other” option. It allows for the respondent to enter in their own reasons for giving the NPS Score.
There are 2 key ideas that apply here:
- Focused Context - We don’t want respondents to ramble on about many different things. We need to identify the primary reason and since the primary reason is not in the option-list, they can enter in the reason.
- Limited Text - We also know that limiting the text to 1-2 lines (like Twitter’s 140 Characters) focuses the customer’s attention and zeros in on the root cause. It also allows for topic identification as opposed to sentiment analysis. We really don’t need any more sentiment analysis - we already know the NPS by now. The key here is accurate topic identification.
Furthermore, we use a data/content dictionary to determine “topics” using an NLP/text model. Again, this would be much more accurate, because we are only looking for “Topics” - that the user has to type in.
AI/ML for Topic Discovery
QuestionPro has partnered with Bryght.ai for this part and will be using that AI/ML model for topic identification. One of the reasons for this is that we’ve worked with Bryght’s team to develop data-dictionaries across multiple and unique verticals - including Gaming, Retail, Gig-Economy, B2B SaaS etc. These customized data-dictionaries based on verticalized industry knowledge gives us better and focused accuracy.
Predictive Suggestions
We also do predictive suggestions, similar to Google Suggest. As users are typing in, we show them what others have suggested. It allows users to simply choose the item, instead of exponentially expanding the data-dictionary.
Predict
So far, with the Identification & Isolation models above, we can deterministically say that the reasons a, b and c are the top reasons why folks are dissatisfied/detractors and hence the assumption is that they all have a 100% propensity to churn. We believe it is logical to use detractors to identify and isolate reasons for churn. We assume that that detractors are already churned and at this point, it would be nearly impossible to prevent that.
The Passive folks are the “Undecided” - they are wavering, but could lean either way. In our prediction model, we further ask the passive folks to choose the exact same set of reasons that the detractors were given. This allows us to compare the Passives to the Detractors and accurately identify and predict the passive folks that will churn.
Let's take a real example and go through this; Let's assume that there are 5 reasons for Detractors have chosen:
- Poor Service [80%]
- Dirty Tables [30%]
- Insufficient Menu Choices [18%]
- Pricey & Expensive [12%]
- Location [21%]
These percentages won’t add up to 100 because we’ve allowed users to choose upto 3 reasons for giving a Detractor Score. As described above, this isolation model can be anywhere from 1 -3 (Choose the top reason or the top 2 or reasons.)
For the Passives; let’s say our distribution falls as below
- Poor Service [22%]
- Dirty Tables [10%]
- Insufficient Menu Choices [10%]
- Pricey & Expensive [20%]
- Location [20%]
Anecdotally looking at the data, we can say that Poor Service, Dirty Tables and Location are the top reasons someone will be a detractor. This also means that anyone Passive, who chooses those three items is likely to be a detractor in the next visit or in the upcoming months. There are other factors weighting against that decision, but in the absence of other counterbalancing factors, all passives who select those options are candidates for churn.
We use this model to predict Churn - the % of Passive folks who select the same “reasons” as marked as “Churn Predictors”. It gives you a predictive model on who probably will churn.
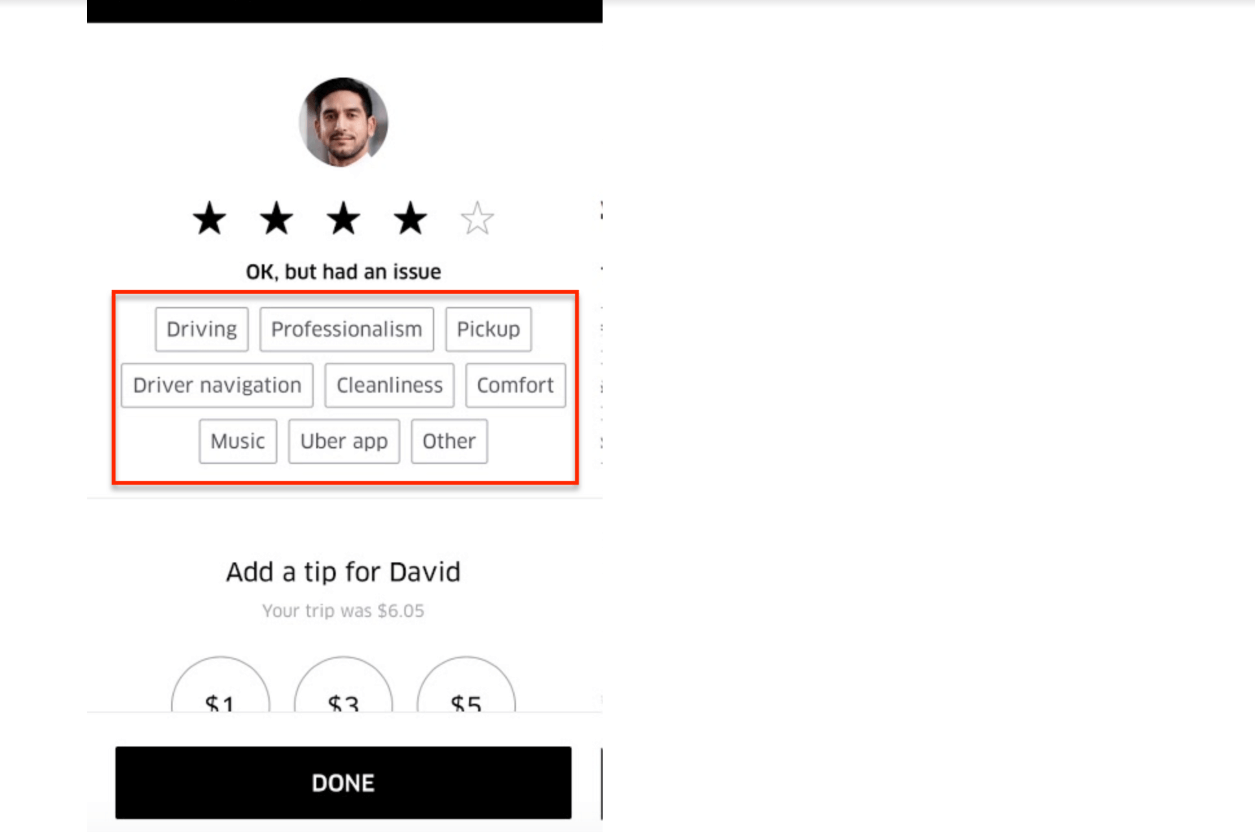
Uber : Live Examples of Churn Identification
Uber uses a simplisting identification model for both promoter and detractor root-cause identification.
In the screenshot above, the user gave a 4 Star Rating. Assuming 3 & 4 Stars are passives, Uber is now trying to determine the root cause of the 4-Star rating using a simple choice model.
Conclusion
While the efficacy of NPS has been debated for over 15+ years now, the underlying model for segregation customers between “Advocates” - “Lurkers” and “Haters” is a fundamental construct in satisfaction and loyalty modeling. The Churn modeling that we propose is fundamentally based on the premise that “Lurkers” can be swayed, either to be “Advocates” or not.
The predictive model fundamentally relies on the principle that indifferent customers are the highest propensity to churn. In fact even more so than passionate haters. We rely on this fundamental psychological precept to model our predictive churn process.
 Survey Software
Easy to use and accessible for everyone. Design, send and analyze online surveys.
Survey Software
Easy to use and accessible for everyone. Design, send and analyze online surveys.
 Research Suite
A suite of enterprise-grade research tools for market research professionals.
Research Suite
A suite of enterprise-grade research tools for market research professionals.
 Customer Experience
Experiences change the world. Deliver the best with our CX management software.
Customer Experience
Experiences change the world. Deliver the best with our CX management software.
 Employee Experience
Create the best employee experience and act on real-time data from end to end.
Employee Experience
Create the best employee experience and act on real-time data from end to end.