




How often do researchers look for the right survey respondents, either for a market research study or an existing survey in the field? The sample or the respondents of this research may be selected from a set of customers or users that are known or unknown.
You may often know your typical respondent profile but don’t have access to the respondents to complete your research study. At such times, researchers and research teams reach out to specialized organizations to access their panel of respondents or buy respondents from them to complete research studies and surveys.
These could be general population respondents that match demographic criteria or respondents based on specific criteria. Such respondents are imperative to the success of research studies.
This article discusses in detail the different types of samples, sampling methods, and examples of each. It also mentions the steps to calculate the size, the details of an online sample, and the advantages of using them.
Content Index
- What is a sample?
- Types of samples: Sample selection methodologies with examples
- How to determine a sample size
- Calculating sample size
- Sampling advantages
What is a Sample?
A sample is a smaller set of data that a researcher chooses or selects from a larger population using a pre-defined selection bias method. These elements are known as sample points, sampling units, or observations.
Creating a sample is an efficient method of conducting research. Researching the whole population is often impossible, costly, and time-consuming. Hence, examining the sample provides insights the researcher can apply to the entire population.
For example, if a cell phone manufacturer wants to conduct a feature research study among students in US Universities. An in-depth research study must be conducted if the researcher is looking for features that the students use, features they would like to see, and the price they are willing to pay.
This step is imperative to understand the features that need development, the features that require an upgrade, the device’s pricing, and the go-to-market strategy.
In 2016/17 alone, there were 24.7 million students enrolled in universities across the US. It is impossible to research all these students; the time spent would make the new device redundant, and the money spent on development would render the study useless.
Creating a sample of universities by geographical location and further creating a sample of these students from these universities provides a large enough number of students for research.
Typically, the population for market research is enormous. Making an enumeration of the whole population is practically impossible. The sample usually represents a manageable size of this population. Researchers then collect data from these samples through surveys, polls, and questionnaires and extrapolate this data analysis to the broader community.
LEARN ABOUT: Survey Sampling
Types of Samples: Selection methodologies with examples
The process of deriving a sample is called a sampling method. Sampling forms an integral part of the research design as this method derives the quantitative and qualitative data that can be collected as part of a research study. Sampling methods are characterized into two distinct approaches: probability sampling and non-probability sampling.
Probability sampling methodologies with examples
Probability sampling is a method of deriving a sample where the objects are selected from a population-based on probability theory. This method includes everyone in the population, and everyone has an equal chance of being selected. Hence, there is no bias whatsoever in this type of sample.
Each person in the population can subsequently be a part of the research. The selection criteria are decided at the outset of the market research study and form an important component of research.
LEARN ABOUT: Action Research
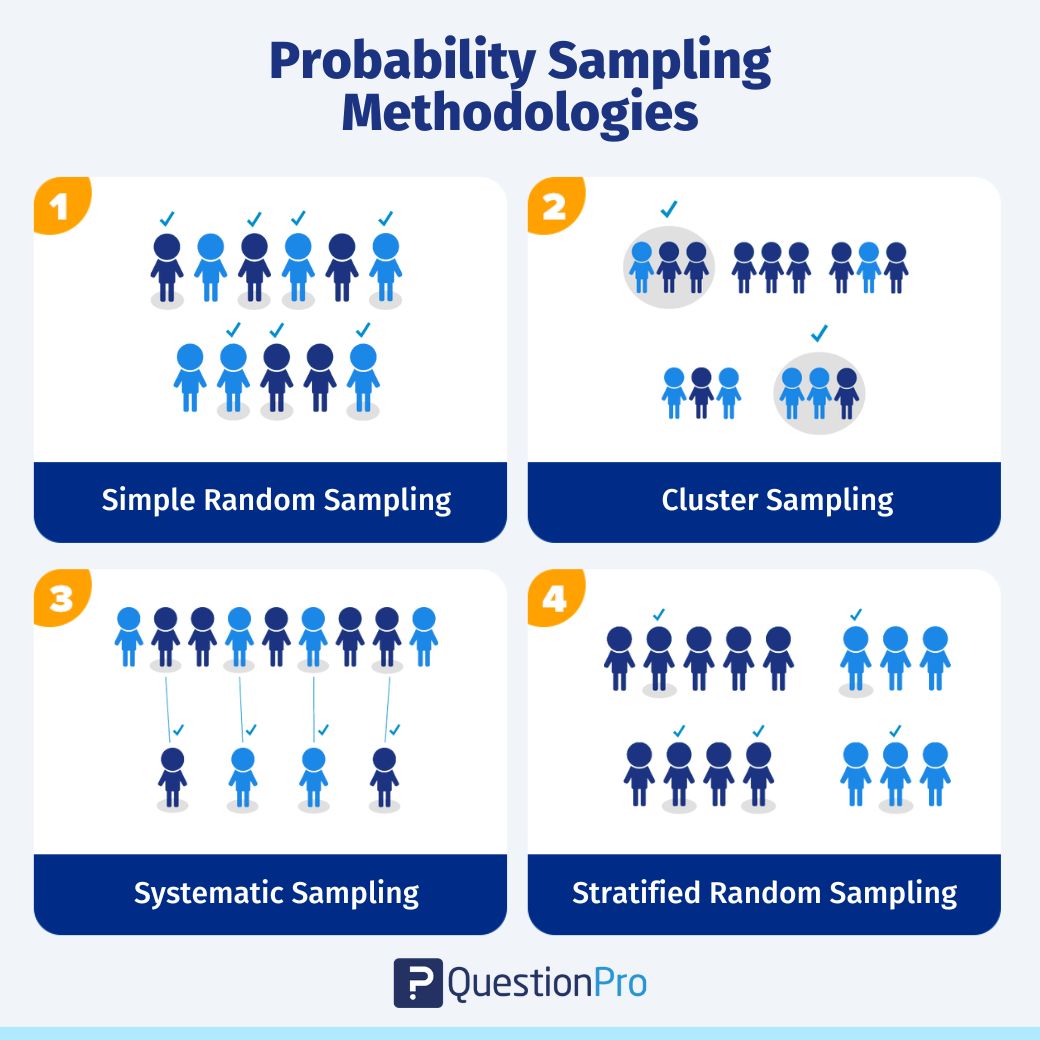
Probability sampling can be further classified into four distinct types of samples. They are:
- Simple random sampling: The most straightforward way of selecting a sample is simple random sampling. In this method, each member has an equal chance of participating in the study. The objects in this sample population are chosen randomly, and each member has the same probability of being selected. For example, if a university dean would like to collect feedback from students about their perception of the teachers and level of education, all 1000 students in the University could be a part of this sample. Any 100 students can be selected randomly to be a part of this sample.
- Cluster sampling: Cluster sampling is a type of sampling method where the respondent population is divided into equal clusters. Clusters are identified and included in a sample based on defining demographic parameters such as age, location, sex, etc. This makes it extremely easy for a survey creator to derive practical inferences from the feedback. For example, if the FDA wants to collect data about adverse side effects from drugs, they can divide the mainland US into distinctive cluster analysis, like states. Research studies are then administered to respondents in these clusters. This type of generating a sample makes the data collection in-depth and provides easy-to-consume and act-upon, insights.
- Systematic sampling: Systematic sampling is a sampling method where the researcher chooses respondents at equal intervals from a population. The approach to selecting the sample is to pick a starting point and then pick respondents at a pre-defined sample interval. For example, while selecting 1,000 volunteers for the Olympics from an application list of 10,000 people, each applicant is given a count of 1 to 10,000. Then starting from 1 and selecting each respondent with an interval of 10, a sample of 1,000 volunteers can be obtained.
- Stratified random sampling: Stratified random sampling is a method of dividing the respondent population into distinctive but pre-defined parameters in the research design phase. In this method, the respondents don’t overlap but collectively represent the whole population. For example, a researcher looking to analyze people from different socioeconomic backgrounds can distinguish respondents by their annual salaries. This forms smaller groups of people or samples, and then some objects from these samples can be used for the research study.
LEARN ABOUT: Purposive Sampling
Non-probability sampling methodologies with examples
The non-probability sampling method uses the researcher’s discretion to select a sample. This type of sample is derived mostly from the researcher’s or statistician’s ability to get to this sample.
This type of sampling is used for preliminary research where the primary objective is to derive a hypothesis about the topic in research. Here each member does not have an equal chance of being a part of the sample population, and those parameters are known only post-selection to the sample.
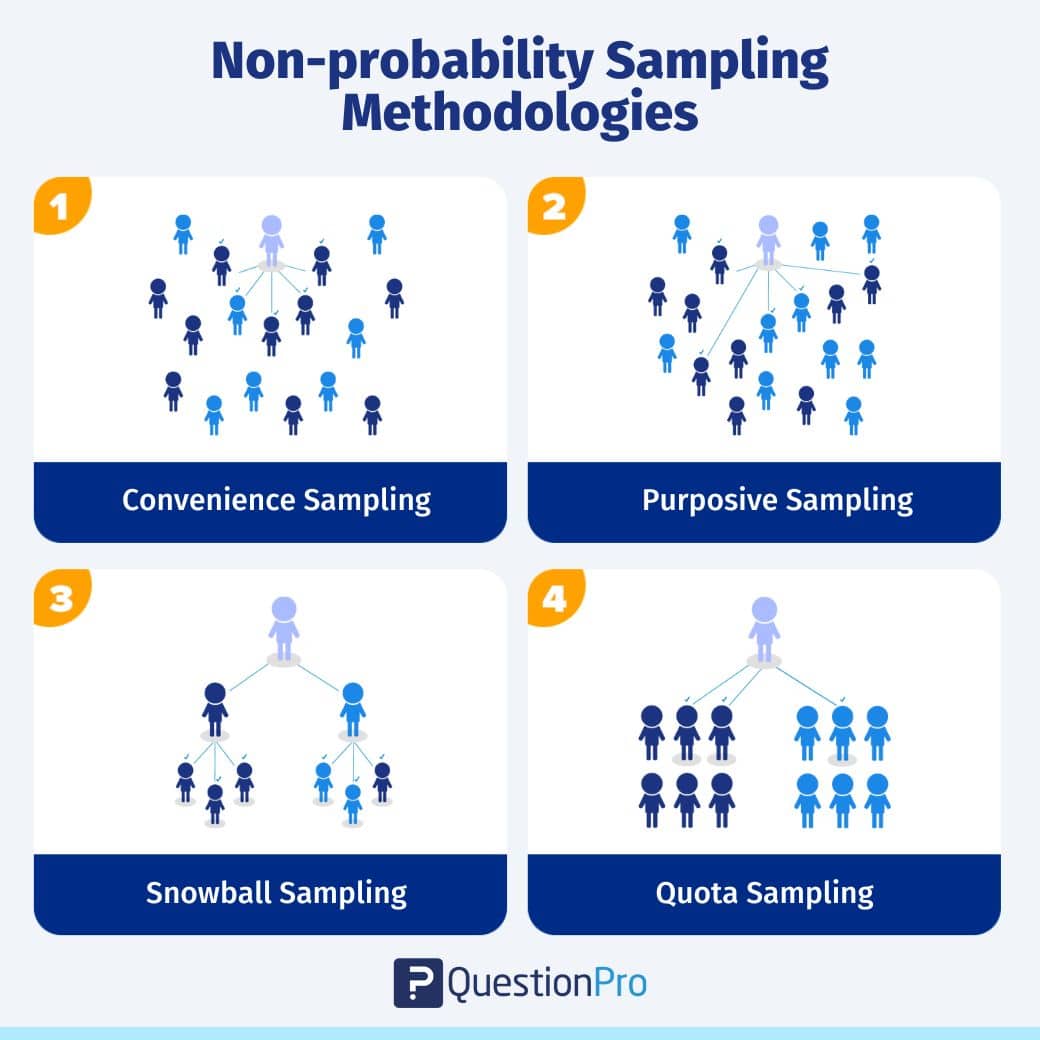
We can classify non-probability sampling into four distinct types of samples. They are:
- Convenience sampling: Convenience sampling, in easy terms, stands for the convenience of a researcher accessing a respondent. There is no scientific method for deriving this sample. Researchers have nearly no authority over selecting the sample elements, and it’s purely done based on proximity and not representativeness.
This non-probability sampling method is used when there is time and costs limitations in collecting feedback. For example, researchers that are conducting a mall-intercept survey to understand the probability of using a fragrance from a perfume manufacturer. In this sampling method, the sample respondents are chosen based on their proximity to the survey desk and willingness to participate in the research.
- Judgemental/purposive sampling: The judgemental or purposive sampling method is a method of developing a sample purely on the basis and discretion of the researcher purely, based on the nature of the study along with his/her understanding of the target audience. This sampling method selects people who only fit the research criteria and end objectives, and the remaining are kept out.
For example, if the research topic is understanding what University a student prefers for Masters, if the question asked is “Would you like to do your Masters?” anything other than a response, “Yes” to this question, everyone else is excluded from this study.
- Snowball sampling: Snowball sampling or chain-referral sampling is defined as a non-probability sampling technique in which the samples have rare traits. This is a sampling technique in which existing subjects provide referrals to recruit samples required for a research study.
For example, while collecting feedback about a sensitive topic like AIDS, respondents aren’t forthcoming with information. In this case, the researcher can recruit people with an understanding or knowledge of such people and collect information from them or ask them to collect information.
- Quota sampling: Quota sampling is a method of collecting a sample where the researcher has the liberty to select a sample based on their strata. The primary characteristic of this method is that two people cannot exist under two different conditions. For example, when a shoe manufacturer would like to understand millennials’ perception of the brand with other parameters like comfort, pricing, etc. It selects only females who are millennials for this study as the research objective is to collect feedback about women’s shoes.
How to determine a Sample Size
As we have learned above, the right sample size determination is essential for the success of data collection in a market research study. But is there a correct number for the sample size? What parameters decide the sample size? What are the distribution methods of the survey?
To understand all of this and make an informed calculation of the right sample size, it is first essential to understand four important variables that form the basic characteristics of a sample. They are:
- Population size: The population size is all the people that can be considered for the research study. This number, in most cases, runs into huge amounts. For example, the population of the United States is 327 million. But in market research, it is impossible to consider all of them for the research study.
- The margin of error (confidence interval): The margin of error is depicted by a percentage that is a statistical inference about the confidence of what number of the population depicts the actual views of the whole population. This percentage helps towards the statistical analysis in selecting a sample and how much sampling error in this would be acceptable.
LEARN ABOUT: Research Process Steps
- Confidence level: This metric measures where the actual mean falls within a confidence interval. The most common confidence intervals are 90%, 95%, and 99%.
- Standard deviation: This metric covers the variance in a survey. A safe number to consider is .5, which would mean that the sample size has to be that large.
Calculating Sample Size
To calculate the sample size, you need the following parameters.
- Z-score: The Z-score value can be found here.
- Standard deviation
- Margin of error
- Confidence level
To calculate use the sample size, use this formula:

Sample Size = (Z-score)2 * StdDev*(1-StdDev) / (margin of error)2
Consider the confidence level of 90%, standard deviation of .6 and margin of error, +/-4%
((1.64)2 x .6(.6)) / (.04)2
( 2.68x .0.36) / .0016
.9648 / .0016
603
603 respondents are needed and that becomes your sample size.
Try our sample size calculator to give population, margin of error calculator, and confidence level.
LEARN MORE: Population vs Sample
Sampling Advantages
As shown above, there are many advantages to sampling. Some of the most significant advantages are:
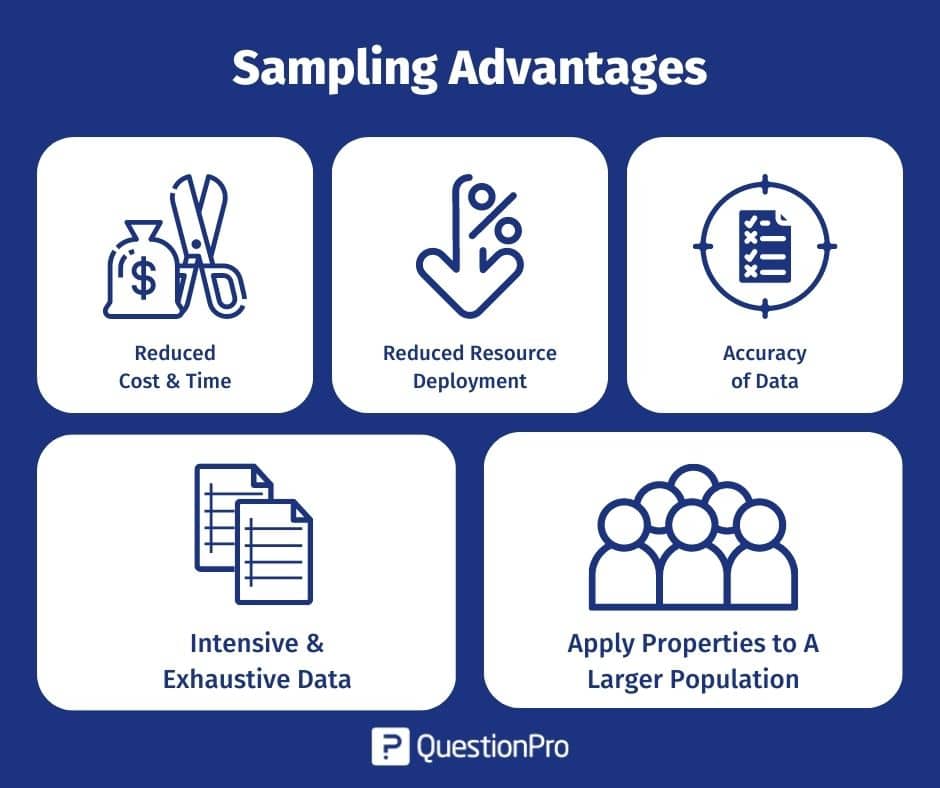
- Reduced cost & time: Since using a sample reduces the number of people that have to be reached out to, it reduces cost and time. Imagine the time saved between researching with a population of millions vs. conducting a research study using a sample.
- Reduced resource deployment: It is obvious that if the number of people involved in a research study is much lower due to the sample, the resources required are also much less. The workforce needed to research the sample is much less than the workforce needed to study the whole population.
- Accuracy of data: Since the sample indicates the population, the data collected is accurate. Also, since the respondent is willing to participate, the survey dropout rate is much lower, which increases the validity and accuracy of the data.
- Intensive & exhaustive data: Since there are lesser respondents, the data collected from a sample is intense and thorough. More time and effort are given to each respondent rather than collecting data from many people.
- Apply properties to a larger population: Since the sample is indicative of the broader population, it is safe to say that the data collected and analyzed from the sample can be applied to the larger population, which would hold true.
To collect accurate data for research, filter bad panelists, and eliminate sampling bias by applying different control measures. If you need any help arranging a sample audience for your next market research project, contact us at [email protected]. We have more than 22 million panelists across the world!
Conclusion
In conclusion, a sample is a subset of a population that is used to represent the characteristics of the entire population. Sampling is essential in research and data analysis to make inferences about a population based on a smaller group of individuals. There are different types of sampling, such as probability sampling, non-probability sampling, and others, each with its own advantages and disadvantages.
Choosing the right sampling method depends on the research question, budget, and resources is important. Furthermore, the sample size plays a crucial role in the accuracy and generalizability of the findings.
This article has provided a comprehensive overview of the definition, types, formula, and examples of sampling. By understanding the different types of sampling and the formulas used to calculate sample size, researchers and analysts can make more informed decisions when conducting research and data unit of analysis.
Sampling is an important tool that enables researchers to make inferences about a population based on a smaller group of individuals. With the right sampling method and sample size, researchers can ensure that their findings are accurate and generalizable to the population.
Utilize one of QuestionPro’s many survey questionnaire samples to help you complete your survey.
When creating online surveys for your customers, employees, or students, one of the biggest mistakes you can make is asking the wrong questions. Different businesses and organizations have different needs required for their surveys.
If you ask irrelevant questions to participants, they’re more likely to drop out before completing the survey. A questionnaire sample template will help set you up for a successful survey.


